
HOME >> Pythonをさわってみよう > O市のコロナ患者発生状況の解析
Pythonをさわってみよう O市のコロナ患者発生状況の解析
Python と言うプログラム言語をさわっています。 学習と言うにはおこがましいのですが、ただ単に触るだけでは面白くないので、身近なテーマを使ってその使い方を実感することにしました。 このいきさつは「Pythonを触ってみよう まず基礎から」(2022/7/29)で説明しています。
今回は、隣の街のO市のデータを使って同じような操作を実施したのですが、これはすんなりとはいきませんでした。 NGとなるほど、意欲が湧きますね!
 .
.
■ O市の感染者発生件数のデータ
O市のホームページには、右の様なPDFファイルとして、データが公開されています。
ただ、件数が多いのか日毎のデータとして、別ファイルで公開されていいますので、ダウンロードするにも少し手間がかかりました。 ダウンロードの手間は仕方がないとしても、解析の手間は簡単にしたいですが・・・・・・・。
● トライ1
先回のA市で実施した同じPDFファイル形式であったので、ある日にちのデータを同様な方法で解析したのですが、なぜだか出力データがゼロの羅列でした。 使用したプログラムは、「Pythonを触ってみよう 情報取込み方法 超簡単だ」(2022/8/7)です。
・・・・・・・・・・・・なんで?
● トライ2
そこで、PDFで取り込んだデータを中間ファイルとしてCSVファイルに書き出してみた。 すると、表のデータは取込んでいるのですが、ページ毎のデータの欄がドンドン移動しており、どの欄が該当する項目なのか分からなくなっていました。
いろいろ調べてみると、tabulas で取込んだPDFページは、Excelのシートに分配されているいることが分かりました。 そして、データフレームとして集計を実施した pandas がこのシートごとのデータ処理を正確に実施できないことではないかと推定しました。
● トライ3
そこで、PDFファイルをあらかじめExcelに変換しておいて、シート毎のデータをコピー/ペーストでひとつの表としてまとめてしまおうとしました。
ただ、面倒な作業ですが、pandas はこのシート毎のデータを連結する手法があることをネットで知りました。 複数のシートのデータを読み込めるのである。
そこで、PDFファイルをExcelファイルに変換する手として、昔購入していた「いきなりPDF]というソフトをインストールしました。 ここで、登録情報が異なるのでもう一台分の追加費用を払えとゴチャゴチャ言ってきたので、古い登録情報を消して新しく登録しなおしました。 何とか正常に機能することを確認しました。 でも疲れたね。 日を改めてトライすることにしました。
● トライ4
何気なしにファイルをめくっている時、camelot のページが目に留まりました。 サンプルに従って記述したプログラムを使って、PDFファイルをCSVファイルに出力してみました。 するとすんなりと、綺麗な表データとして出力されていました。 シード毎に分かれていたデータも連結されていました。
あれあれ・・・・上記のような苦労はどこに?
さらに、メモの内容を見てみると、Ghostscript がありません、とかで一度あきらめた方法でした。 なんと、ボーとしていたのでそんなことを忘れていたのでした。 この内容は、 「Pythonを触ってみよう 情報取込み方法の改善」(2022/8/5)を参照下さい。
****** ボーと生きていても、いいんだよ! ******
そうでした。 このスクリプトはPostScript からPDFに変換する時に必要となる物とのことでした。 しからば何故、今回はすんなりと行ったのでしょうか? そうか! 今回、いきなりPDFというソフトをインストールしたので、これらのPDFに関する環境も整備されたのではないかと、納得することにしました。 怪我の功名だ。
● トライ5
そこで、PDFファイルを直接読込み、集計結果をCSVファイルに出力しました。 しかし、出力は日別のデータですので、この作業を何回も繰り返して、最終的にはExcelの集計ファイルにコピーしていきました。 やっと先回と同じようなグラフを作成する事が出来ました。 でも、後の作業が大変でした。
● トライ6
次の日の朝、トイレの中でボーとして考えていました。 ダウンロードした日別のPDFファイルをいきなりPDFを使って一ヶ月分の一つのファイルに結合してしまえば簡単になるのでは!・・・・・とのアイディアが閃きました。 このソフトは有料なのでいろいろな加工が出来るのです。 ちなみに個別のPDFファイルの大きさは 50KB 前後で、連結したファイルは 2,043KB でしたので問題無さそうです。
でも、期待して実行させたのですが、これまたNGでした。
FileNotFoundError: [Errno 2] No such file or directory: '20220707_0001.pdf'
せっかく作ったファイルが ありませんと・・・・・・・・? でもすぐにその原因に気が付きました。 「測定したデータをリアルタイムでグラフ表示する方法」(2022/6/14)と同じ間違いでした。 ファイルの保管場所が違っていたのでした。
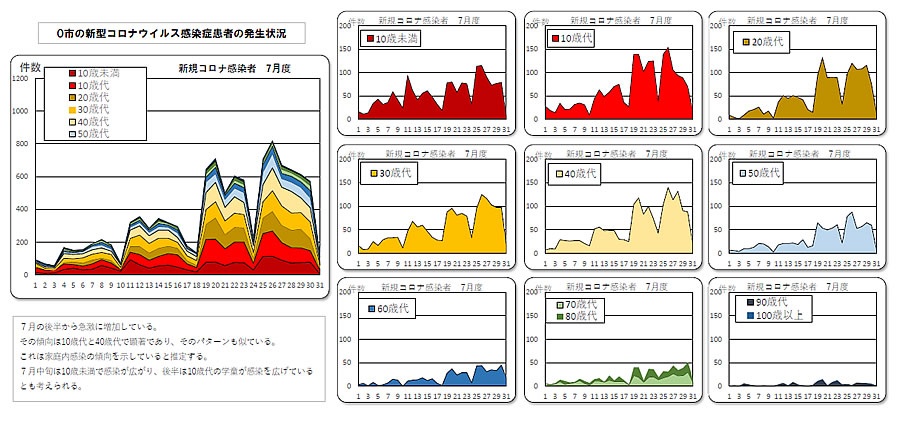
■ O市の感染者発生件数のグラフ
出力までには、かなりの時間がかかりましたが、求めるデータが無事出力されました。 そのデータをExcel を使って整理し、グラフ化したものを下に示します。
***** PDFファイル *****
この時使用した記述を下に示す。
# O市のコロナ患者解析 camelotを使う その2
import pandas as pd
import camelot
file_name = '20220707_0001' #日付けを入力してください。
tables = camelot.read_pdf(file_name+'.pdf', pages='1-end', split_text=True, sprit_text='\r')
dfs = []
for table in tables:
df = table.df
dfs.append(df)
df_all = pd.concat(dfs)
df_all.to_csv('okzk-'+file_name+'-y.csv', index=False, header=True)
data = pd.pivot_table(df_all, index=4, columns=1, aggfunc='count')
data.to_csv('okzk-'+file_name+'-z.csv',index=True)
# 何とか出来たようだが・・・・・。最終出力はやはり重複して出てくる。
■ あとがき
Python の学習のために、身近にあるテーマを取り上げてみましたが勉強になりました。 この後、8月度や9月度のデータもグラフ化し、児童の夏休みがコロナにどう影響したのかが判るといいのですが・・・・・・・・・・。
また、他の都市のデータも興味があります。 市によって公表しているデータ方式が異なるので、これを処理する方法の勉強にもなるのです。