
HOME >> 鉄道模型実験室 > Pythonを触ってみよう 情報取込み方法の改善
鉄道模型実験室 No.216 Pythonを触ってみよう 情報取込み方法の改善
80の手習いとしてPython に触れている。 先回は応用問題として、市のウエブサイトで公開されているPDFファイルからデータ情報を取込み、新型コロナ感染者数の推移グラフを作成することが出来た。 しかし、まだまだ知識と経験に乏しいので、上手に処理することが出来ていません。 その壁となったリスト化する方法について、検討を実施したので報告する。
.
.
■ camelot モジュールを使ってみた
先回の壁となった不特定な半角スペースを含む文字列の中から、文字だけを取り出してリスト化する方法を見い出せれば、さらに自動化が可能となります。 そこで、ネットで検索してみると、camelot と言うモジュールを使ってPDFの表からcsvやExcel に変換する方法が紹介されていました。 PDFの表からcsv形式のデータが取り出せると言うことであれば願ってもない操作なのです。 csv形式であれば、行内のデータがコンマ区切りとして記述されているからです。 すると、壁となっていた課題が一挙に解決するので、早速検討してみることにしました。
Python の作業環境(IDE)は、JupyterLab を使用しています。
そのネット情報をもとに、camelot-py モジュールをインストールした。
pip install camelot-py[cv]
そして、コマンドを実行してみると、 Ghostscrip がインストールされていませんとのエラーが出てきた。 またまた、知らな言葉が出てきたので、これもネットで検索してみると、PostScript からPDFに変換する時に必要となるのだそうだ。 エー? PostScript ! 懐かしい!
40年ほど前に、マッキントッシュを触っていたころ、プリンタへの印刷には、このPostScript のソフトが必要であったと記憶している。 Windows95 が出る前の話である。 コンピュータからプリンタへの出力命令は、この PostScript を通していたと記憶いている。 そして、PDFファイルもこの仕組みを応用し、印刷できる成果物は全てPDFファイルとして作成できると言われていた。 Word だろうが一太郎であるが、それらで作成された書類は、PDFファイルに変換でき、かつ、後からファイルの内容を変更できないのもこのためである。 印刷されて書類と一緒なのである。
そうか! このPDFファイルをいじることは、何らかの点で、PostScript のお世話になると言うことか。 納得!
*****************************************************
そこで、 Ghostscrip をインストールして命令を実行したのであるが、エラーは出ないものの、いつまでたってもパソコンはダンマリ状態であった。 ネットで紹介されていた方法を参考にしたつもりであるが、パソコンの環境やソフトの具合がマッチしていないと考えるが、それを解決する力を持ち合わせていないので、さっさと諦めることにしたのである。
でも、収穫はありました。 参考とした記述方法として、append とか concat と言ったコマンドを駆使することでした。
tables = camelot.read_pdf(---省略--) # pdfファイルの1頁から最終頁までリストで習得する
dfs = []
for table in tables: # 1頁毎にDataFrame形式に変換後、リストに追記してゆく
df = tables.df
dfs.append(df)
df_all = pd.concat(dfs) # リストの各要素(各頁)を結合
なお、最初に pandas も pd としてインポートしていました。 そして、記述の内容については理解できていませんが もしかして、先回実施した tabula の場合でもこの方法が使えるのではないかと考えて、まずは試しに実行してみることにしました。
■ Tabula-py をもう一度使ってみる
先回実施した Tabula-py モジュールを使用する状態に戻ってみました。 そして、上記の記述に倣って実行してみました。
● PDF全頁を一度にcsvファイルとして取込む
まず、最初の課題であるPDF全頁を一度にcsvファイルとして取込む方法について検討しました。 最初はエラーばかりでしたが、df = tables.df の部分が理解出来ていないので、試しに削って実行してみると、うまく通るようになりました。 そして、csvファイルに書き出してみると、求めるファイルが見事に出来上がっていました。 記述内容と出力されたcsvファイルを下に示す。
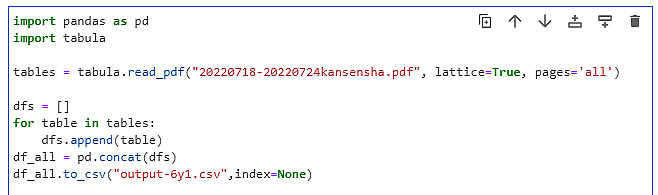
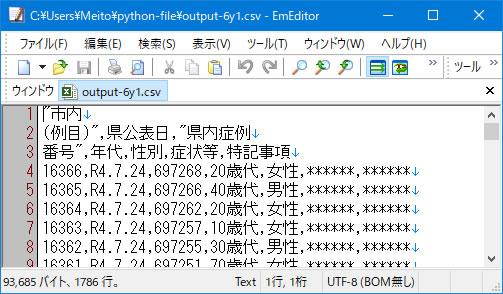
内容を理解せずに実行していますが、目的を達していますのでOKとしましょう。 特に
for table in tables:
が理解できていません。 tables は tabula.read_pdf(xxxx) のコマンドで設定しているのですが、table とは何でしょうか? 内容からは1頁分の表のような気がします。 この命令で各頁の表を取込み、自分が設定した dfs というリストに次々と追加してゆき、最後にそのリストの要素を一つにまとめるという処理と解釈することにします。
 .
.
そう言えば、lines と line とか、pages と page など、今までセットで使っていました。 複数形の変数は定義したのに単数形の変数はどこで定義していたのでしょうか不思議です。
これは、単数形とか複数形の問題ではなく、読込んだ変数(ここでは複数形で示した変数)の中に、単数形の変数があるかどうかをチェックしているようです。 この単数形の変数の定義は、クラスの中のメソッドを読み解かなければならないようですね?・・・・・・・・・・・こりゃたいへんだ。
まあ、この様な記述でも機能しているので、おまじないとして理解しておくことにしましょう。
● 日付データの切り分け
次の課題として、日毎の集計をするために、いつの日のデータかを判別する必要があります。 この日付データは、表データの2列目の欄に記述されていますので、このデータを取込必要があります。
上記のcsv ファイルに示すように、日毎のデータは改行で区切られた一行の中に、コンマ区切りで記述されています。 そこで、この一行、すなわち line のデータをコンマで分割してリストに収め、その2番目の要素の内容を取出せば、それが日付データとなります。
実行したプログラムを下に示します。
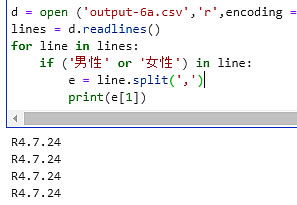
実行結果がセルの下にプリントアウトされていますが、見事に日付データを打ち出しています。 なお、男性 or 女性のチェックはデータ行だけを取出すようにしたものです。
*****************************************
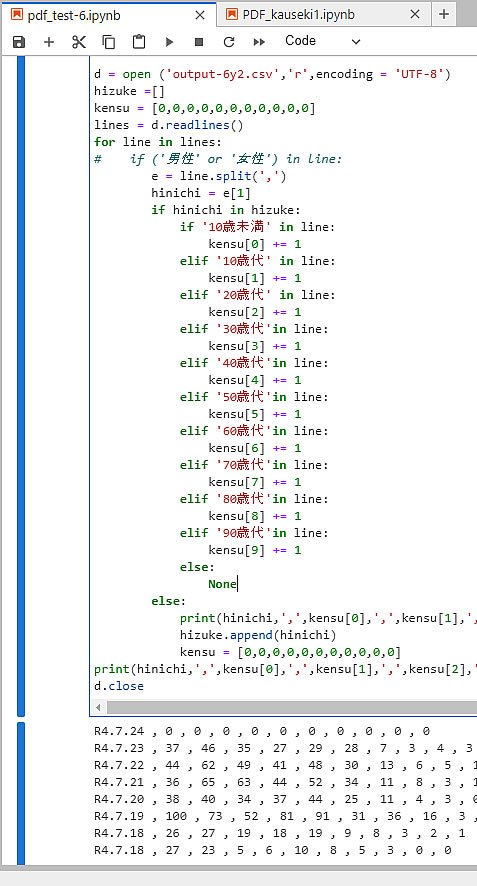
日付データが取込めるようになったので、同じ日付だけの集計が出来るように右のようなプログラムを構成しました。 まず、 hizuke と言うリストを作り、上記で取り出した e[1]のデータ、即ち、hinichi の値をリスト中から探し出ます。 もし、リストの中に同じ日付けがあれば、年代の欄にて選別を実施して、そのカウントアップを実行します。 その内容は先回の報告と同じです。
実行結果をセルの下にプリントアウトしていきます。 でもまだ問題がありました。
- 件数の集計結果の合計が本来の合計と合わなかった。
- そこで、男性 or 女性のチェックを外すと、今度は e[1]がレンジオーバーのエラーとなる。 原因はデータ行でない最初の項目欄も取込んでしまうからである。
- そこで、csvファイルの状態で項目欄を削除して走らせると、綺麗に集計するようになった。
- チェックのため合計を計算すると、どの日付も 1個だけ少ないのである。
- さらに、日付のデータが、一行ズレており、最初の日付の集計はゼロの羅列であった。
上記の4番と5番はプログラムの論理ミスであることに気が付き、IF 文の構成を変更した。
■ 完成したプログラム
四苦八苦した結晶を紹介しよう。 まず、解析しようとするPDFを読込んで、CSVファイルを作成プログラムです。 PDFファイルをPython の作業領域にセットし、拡張子を除いたファイル名をプログラムの中に記入しておきます。 そして、プログラムを走らせます。
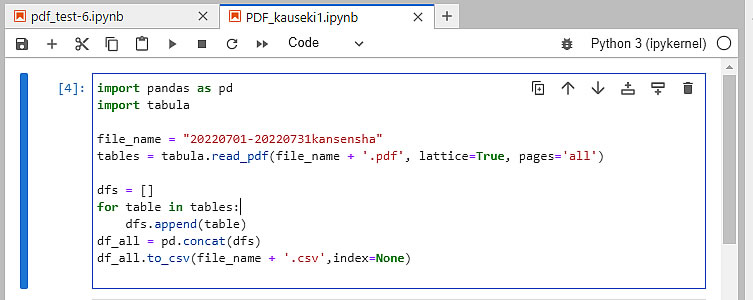
その結果、同じ名前のCSVファイルが作成されているので、その中身をチェックします。 ここで、
チェックポイント: 日付データ毎にまとまっているデータとなっていること。
を確認し、データ行以外の項目などを記述している行を手動で削除しておきます。 日付データがバラバラのリストでは、ソートなどの操作によって整形しておきます。
CSVファイル名を記入してプログラムを走らせます。
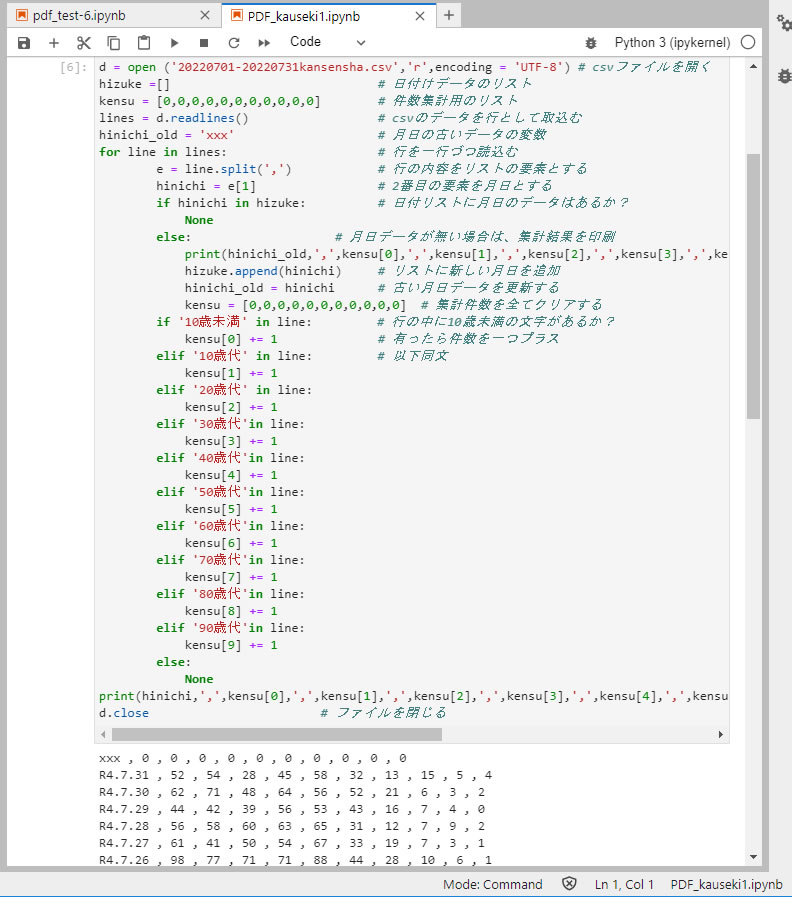
計算結果は、セルの下側に印字されます。 この内容をコピーしてメモ帳にペーストして保存します。 内容はコンマ区切りのCSVファイル形式ですが、拡張子は.csv でも .txt でもかまいません。 そしてこのファイルを Excel に読込んでグラフ化などの処理を実施します。 この部分は大した手間ではないので、手動操作でも充分です。
● 改良したポイント
上のプログラムについて、工夫改良したポイントを説明します。 論理的ミスを犯した IF文の部分について、年代別集計作業の前に、日付データの新旧の処理を実施するように変更しています。
日付データが記載されている e[1]のデータ、即ち、hinichi の値をもとに、hizuke リストに載っているかどうかを調べ、すでに記載されておれば年代別集計作業に進みます。 しかし、記載されていない新しい値であれば、日付別集計は完了したので、集計結果をプリントアウトします。 しかし、その時の日付データは新しいデータとなっていますので、そのままプリントアウトすることが出来ません。 このため、hinichi_old と言う変数を設定しておき、事前に設定しておきます。
その後、新しいデータをこのhizuke リストに追加し、hinichi_old 変数も新しいものに置き換えておきます。 そして、集計リストを全てクリアーしておき、次の年代別集計に進みます。
***********************************************
まだまだ、改良の余地はあると思いますが、とりあえず目的を達したので、今回のプロジェクトは完了といたします。
2022/8/5