
HOME >> Pythonをさわってみよう > T市のコロナ患者発生状況の解析 再挑戦
Pythonをさわってみよう T市のコロナ患者発生状況の解析 再挑戦
Python の使い方を実感するため、近隣の街のコロナ患者発生状況の解析を実施しました。 この中で、中止していたT市の解析にういて、方法をかえて再挑戦しました。
■ T市の解析
先回実施したT市の場合、日毎のデータがHTMLテーブル形式で公開されていました。 そこで、O市の解析プログラムにおいて、対象ファイルの記述ををPDFファイル名から、ホムページのURLに変更するだけで容易に対応できました。
しかし、HTMLのテーブル表示で示されたデータは日毎のデータです。 このため、一ヶ月のデータとするためには、同じ作業を31回も実施する必要があるのです。 これを実施する根気がないので解析をあきらめて中止しました。
今回は、この方法に工夫を加え、日毎のデータを表示しているページのURLリストを事前に作成、そのリストを使って一ヶ月のデータを一気に解析する方法に挑戦することにしました。 少し手間はかかりますが、同じ作業の繰り返しでは無いし、HTML記述の知識を使いながらでの作業ですので、これもWebスクレイピングの学習の一環として実施しました。
 .
.
 .
.
● URLのリストを作る
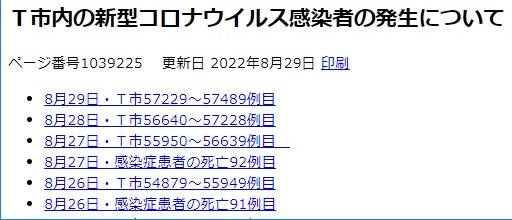
まず、日毎のデータを示すページをリスト様式で記載している部分を探します。 例えば右の様に記載されていたとします。 このページを使ってURLのリストを作ります。 その手順は下記の様に実施しました。
- リスト様式で表示されているページを開く。
- 右クリックしてソースを表示させる。 タグがいっぱい表示されますが、HTML記述のある程度の知識があれば、理解できるはずです。
- ソースの中を探して、リスト記述部分をコピーする。
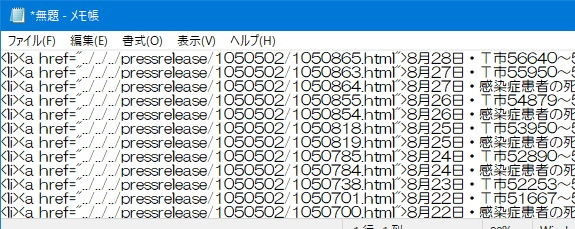
- メモ帳を開き、ペーストする。 その状態を右に示します。
<a href="../../../pressrelease/・・・・・.html">と記述されている部分が取出したいURLです。 - ここからは、HTMLの記述方法を勉強されている方は容易と思いますが、必要の無い部分を消していきます。 使用するのは、置換処理を使いましょう。 一度の操作で実施出来ます。
- なお、この後の処理をミスった時、やり直せるように中間ファイルを作っておきます。 それには、URL、日付け、内容の欄を残しておきます。 日付けの欄は、解析の対象範囲を選択する時に使用する可能性が高いので、最後まで残しておきます。 また内容の欄は、対象としない内容が混ざっている場合、後から選別するために使用します。
- URLのパスは、一般的に右上のような相対パスで記述されています。 解析の時にはこのままでは使えませんので、絶対パスに変更しておきます。 これも、置換の方法を使い、../../../ の部分を https://www.city.***.***.jp/ と置き換えます。 置き換える内容は、ページ上部に表示されていますので、容易に判断できると思います。
- そして、URL、日付け、内容の間にコンマを挿入してCSVファイル形式で保存します。 コンマの挿入も置換処理を使うと簡単に実施できます。
- 保存されたCSVファイルファイルをExcel にて開き、内容欄を元にソートを実施し、対象外のデータを除外します。
- また、日付けをもとに並べ替えておくと、後の処理が楽になります。
- < や > などのタグ記号をPython のリスト記述に使用できるように、置換しておきます。 この状態のExcel ファイルを保存しておきます。
- 解析に使用する時は、対象範囲のURLデータを選択し、また、メモ帳に張り付けます。 今回の場合、一つの日付ページの中に、報告の遅れた数日前のデータも含まれていたので、範囲を広げて選択しておきます。
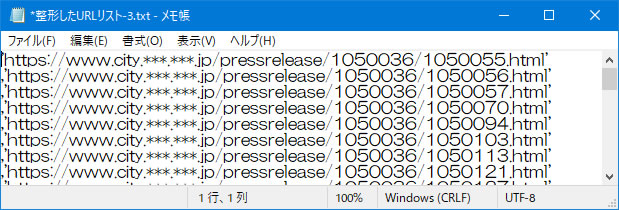
- ここでの作業は、右の様なリストを作るためですが、Python のリスト記述ルールに沿って整理しておきます。
- まず、大切なことは、リスト内に、改行を入れないことです。 右の図では入っている様に見えますよよね。 でも、表示の欄で、右端で折り返すという選択をしているからです。 このチェックを外すと、右のほうに長く伸びたデータ列になります。
- また、各URLデータの間は、半角のコンマを挿入しておく必要があります。 しかし、最後のデータの後は入れてはいけません。 自分は、このルールの確認のために、制御記号を表示できるフリーソフトの EmEditor を併用しています。
- そして、何個のURLデータを記述したのかもメモしておきます。 これは繰り返し処理をする時の範囲指定に使用するからです。
.
● Python での解析処理
事前に作成してURLリストを使って解析を実施します。 Python の記述内容を下に示します。
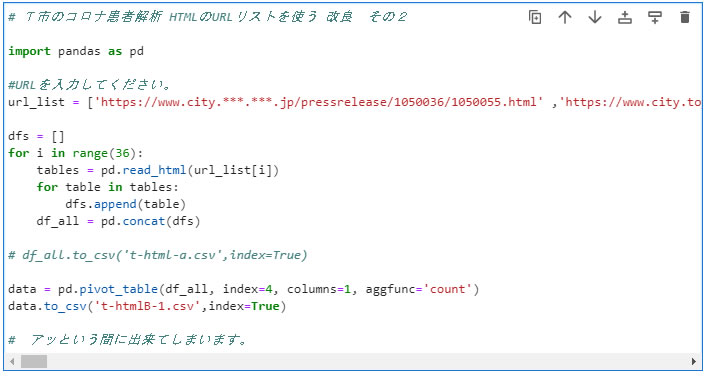
作成しているURLリストを url_list のカッコの中にペーストします。 リストデータには改行記号が入っていませんので、長い一行の文になっています。 そして、一つずつのURLについて解析させるのですが、これを FOR文を使って繰り返し処理させます。 この時の繰り返し回数は、先に数えていたデータ数を range の部分で指定します。 31日分のデータですが、報告が遅れたデータも計算させるため、範囲を広げています。
確認のために処理の中間ファイルを出力するようにも設定できます。 そして、ピボットテーブルの解析では、日付データはゼロから数えて4番になるので、縦の欄の指定として index=4 と指定し、年代欄は横の欄として columns=1 と指定します。
解析結果のCSVファイルを表形式で攻めすと、下の様になります。
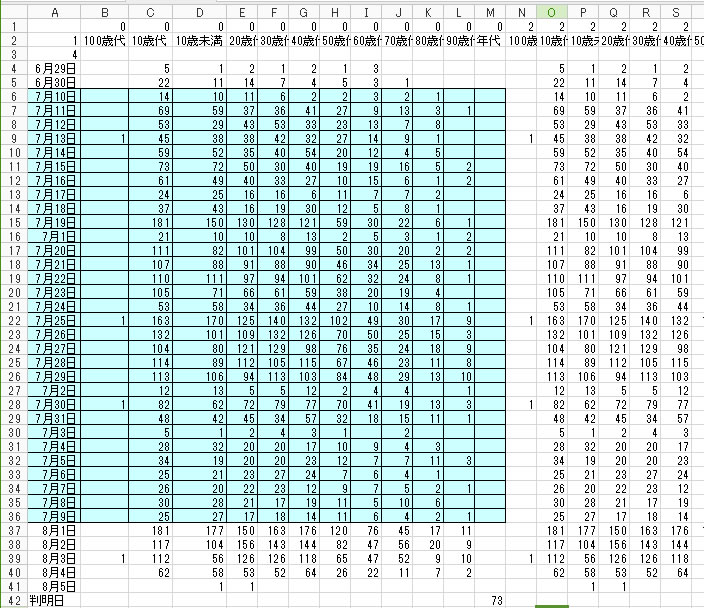
欄の表示順を整理しながら、グラフ表示のためのExcel ファイルにコピペしていきます。 上記の青く囲った範囲が活用するデータです。
■ 解析結果
解析結果を先回と同じようなグラフに表示させました。
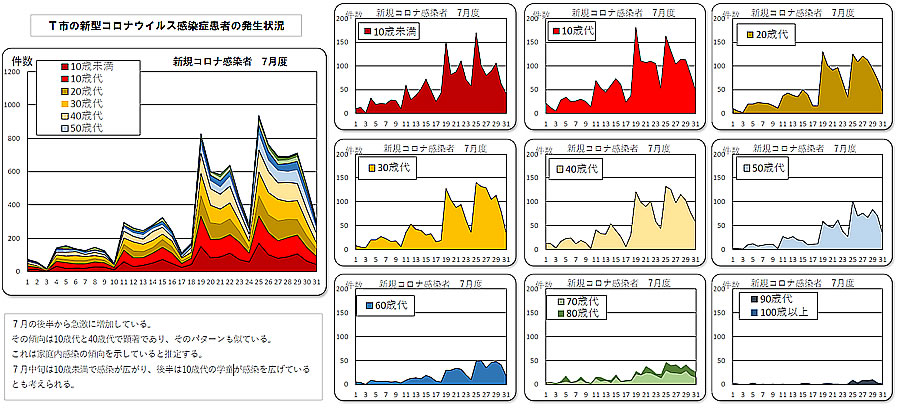
■ まとめ
Web スクレイピングには、事前の処理がPython の解析を容易にしていることを実感しました。 何でもかんでもPython に頼るのは得策ではないようです。
また、目的の一つであった” 第7の初期は、幼稚園児童から広がっている ” という指摘の検証について、グラフからはこの傾向が読み取れませんでした。 これは、近隣の街とは異なる傾向でしたので、なにか地域の事情があるのかも知れません。