
HOME >> Pythonをさわってみよう > 機械学習の実感 マルコフ連鎖用の辞書データ
機械学習の実感 マルコフ連鎖用の辞書データ
苦労して学習したWEBスクレイピング手法の深堀は、ELモデルのリスト作成など実施していましたが、少し気力が薄れてきたのでほどほどにして中断しています。そして、次の目標である機械学習の実感をつかむため、教本の次のステップに進むことにし、今はChapter4 「日本語の文章を生成しよう」に挑戦しています。今回はその中からマルコフ連鎖用の辞書データの作成方法について、まとめておきます。
■ マルコフ連鎖用の辞書データとは?
アンドレイ・マルコフ( 1856-1922 )はロシアの数学者で、特に確率過程論に関する業績で知られる。彼の研究成果は、後にマルコフ連鎖として知られるようになったとのことである。 マルコフ連鎖は、未来の挙動が現在の値だけで決定され、過去の挙動と無関係であるとのことで、今後起こる状態変化を予測する手法として様々な分野に応用されているとのことらしい(専門家ではないのでよくわかりません)。
自分は、現在のAIブームの中で、その基礎となっている(?、と思っている)機械学習の原理を知ろうとしているのですが、
「日本語の文章を生成しよう」・・・・・・・すなわち、パソコンが自動的に日本語の文章を作ってくれる・・・・・・・
本当に? コンピュータのプログラムが指定されたように作っているだけでは無いの? その方法とは? 貴殿も興味ありませんか?
******************************************************
機械学習ですから、多くのデータを元にして文章の構成などを学習し、その結果を使って文章を自動的に生成することは可能と思います。でも、それはどのようなロジックで実施しているのだろうか。この機械学習の基本的なロジックについて、この教本に解説されていました。 今回はその内容を追って行き、自分なりに理解した内容を忘れないように記録していきたいと思います。
手に取っている教本:
- 書名: いちばんやさしいPython機械学習の教本第2版
- 出版社: 株式会社 インプレス
- 著者: 鈴木たかのり氏、降籏洋行氏、平井孝幸氏、株式会社ビープラウド
第4章では、いろいろな項目がありますが、今回は、多くのデータを元にして文章の構成などを学習した結果をまとめた辞書データの作成方法について、まとめました。
■ 辞書データの作成方法
教本では、多くのイラストを使って分かりやすく説明されていますが、ここでは自分なりに理解したロジックをイラストにまとめてみました。
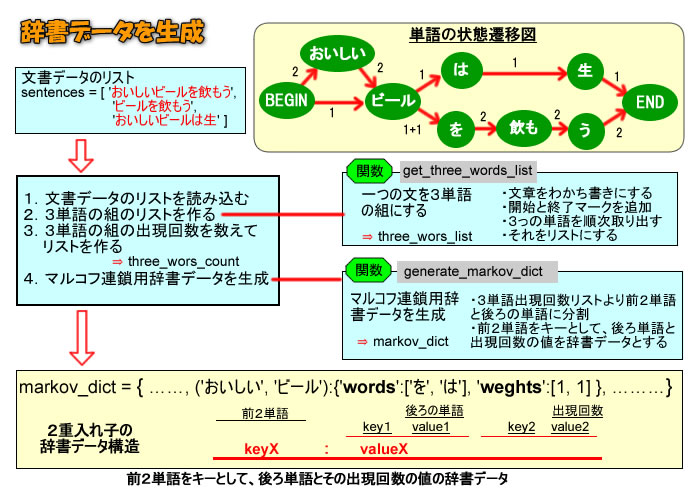
尚、初めての方には、このイラストだけではその内容を理解できないと思います。教本では、日本語の文章を単語ごとに分解するわかち書きの処理方法や、自然言語処理で使用されている Bag of Words などについて事前に丁寧に説明されていますので、ここでは、これらの考え方を理解したものとして話を進めます。
***************************************************
ロジックの考え方をまとめると
- 日本語文章を単語毎のわかち書きに分解する。
- 文章の初めと終わりに開始と終了のマークを付与する。
- その単語を前から順番に3個毎の組にしてリストを作っていく。
- 全ての文章より、同じ3個組の出現回数をカウントして、回数のリストを作る。
- 3個組の中の単語のうち、前2個と後ろの単語に分割し、前2個の単語をキーとして、後ろの単語の出現回数をカウントする。
- この出現回数のリストを辞書データリストとしてまとめる。
なんだかややこしい事をやっているが、なるほどと思った。文章の構成を学校で習った名詞、動詞、修飾語などの文法に従って解析するのではなくて、単語のつながりをその出現回数を追って行って、データ化するという確率論的なロジックなのである。このような確率論的なアプローチによって、人工知能は進化したので、データ量が多いほど内容が濃くなっていくことが理解できる。
上のイラストの例では、”おいしいビール”と続いた後の単語は、”を”の場合が1例、”は”の場合が1例あった事を辞書形式のリストに記憶したことを示している。
***************************************************
それにしても、文章を3単語の組にし、その中の前2組から後ろの単語の出現確率を求めておく。そして、それを文章の自動生成用の確率データにするといるアイディアは素晴らしいと思いました。
このようなロジックにしたのは、日本語には「てにをは」などの助詞があり、直前の1単語だけで次の単語を決めると、意味のある文章になりにくいためとの事である。 即ち、直前の2つの単語から次の単語を取得するロジックとしているのである。
■ 実際のプログラムの内容
ここでは、Pythonの学習のために、教本に示された内容を追って行こう。 内容は、「Lesson 31 マルコフ連鎖用の辞書データを作成しましょう」を実施していきます。この本では、各ステップでのプログラムの記述の後に、その結果としての出力をプリントアウトしているので、プログラムの実行内容を理解することが出来ます。わかりやすいですね。
●ステップ1:
ひとつの文章を分かち書きにした単語リストを作り、さらに開始と終了のマークを追加します。そして、その単語リストの前から順番に3個毎の単語の組にしてリストを作っていきます。
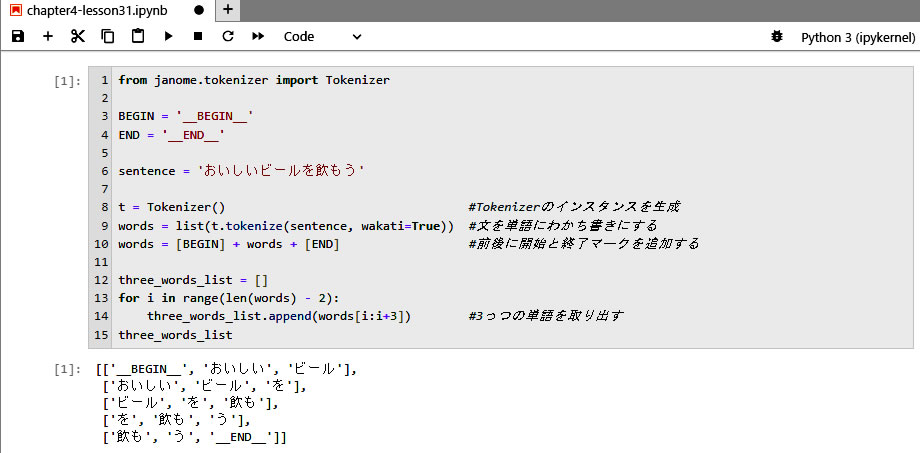
- 文章の中の単語を3個毎の組にして、それをリスト( three_words_list )として出力されていることがわかる。
- 使用するライブラリーは、日本語の形態素解析ツールとして Janome の Tokenizer をインポートする。
- 開始と終了マークとして、BEGIN と END を追加しているが、なぜ、二重アンダースコアを使用しているのだろうか?
●ステップ2:
多くの文章を処理するために、ステップ1の処理を関数化しておく方法に変更し、同じ3個組の出現回数をカウントして、回数のリストを作る。
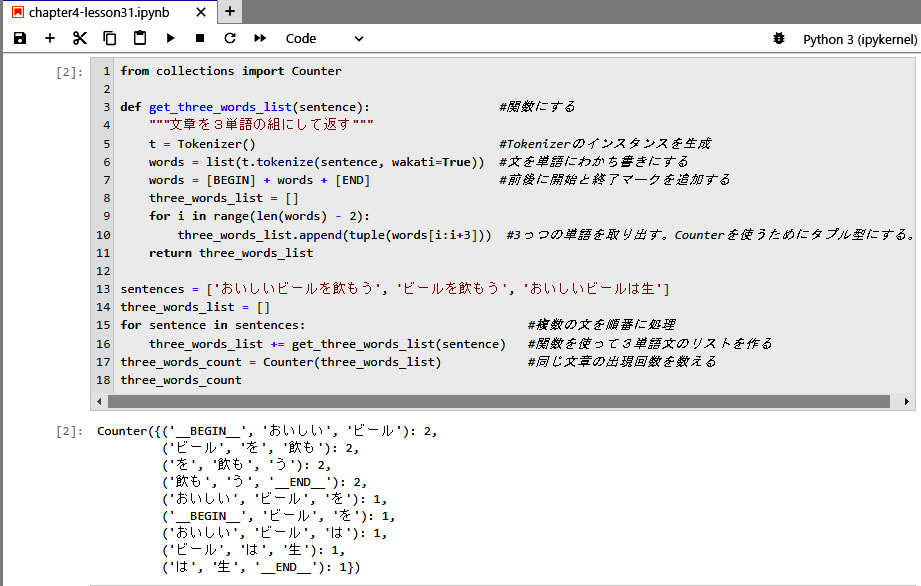
- 出現回数をカウントするために、collection モジュールの Counter クラスをインポートする。
- ステップ1の処理を関数にしておく。
- 複数の文章を順番に読み込み、3単語文のリスト( three_words_list )の中に追加してゆく。
- 17行目、出現回数をカウントして新たなリストを作成する。カウントの命令はこの一行でよいのだ・・・・・・・・・。
- この Counter クラス使用にあたっての注意として、10行目に注目してください。
- 関数化の記述のためにステップ1の内容をコピー/ペーストして実行したらエラーが出てしまいました。その内容はよく理解できませんでしたが、使用するデータに問題がありそうでした。そこで、教本を見ると、tuple の文字が追記されていることが分かりました。タプル、即ち、後から要素の値を変更できないリストのことです。
- Counter クラスの説明では、カウント対象はカプル形である必要があったのでした。
- プリントアウトされた three_words_count の内容を見ると、丸かっこと波かっこが使われていることが分かります。 丸かっこはタプル型のリストを表し、波かっこは辞書型のリストを表しています。
- 即ち、3単語文をキーとし、その出現回数を値とした辞書型データを出力しています。
●ステップ3:
この処理ロジックの核心部分となるマルコフ連鎖用の辞書データを作っていきます。
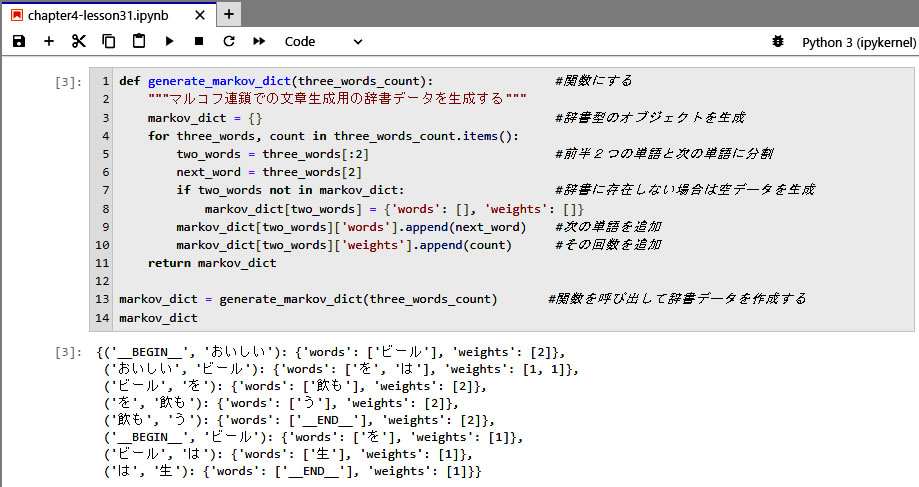
- 1行目、メインの処理部分を関数としておく。
- 3行目、出力としての辞書型リスト markov_dict を生成する。
- 4行目、ステップ2で作成した three_words_count 辞書型データから、キーと値のセットを取り出す。 items() のメソッド。 キーを three_words とし、値を count として取出している。
- 5行目、取出した three_words の前の2単語を two_words とし、
- 6行目、後ろの単語を next_word とする。
- 7行目、取出した two_words が辞書である markov_dict に無い場合は、
- 8行目、新たに空の辞書データを追加する。その時の辞書データのキーを two_words とし、値は右側の波カッコのデータである。即ち、辞書型リストをネスト(入れ子)にするのである。
- 9行目、入れ子にした辞書データのキーの 'words' には、 next_word を値として追加し、
- 10行目、キーの 'weights' には、 count を値として追加する。
- 11行目、以上の処理を取り出したすべてのセットに対して実施して、for ループを完了し、辞書データ markov_dict をこの関数の出力とする。
- この例では、2単語のtwo_words が重複したのは、(’おいしい’, ’ビール’)の場合だけであり、その next_word は、’を’と ’は’ が一回づつ出現したので、
('おいしい', 'ビール'): {'words': ['を', 'は'], 'weights': [1, 1]},
と辞書データが生成されたのである。他の場合は、ステップ2でカウントしたデータを単に記述形式を変えただけに過ぎないと理解している。でも、append() のメソッドで上記のような処理ができるのか不思議である。ネットや他の教則本を調べたが、やはり理解できなかったので、この処理はおまじないとして理解おこう
■まとめ
目的とする「文章の自動生成」プログラムの前半部分を見てきた。そのロジックは、なるほどと感心する内容であった。そして、次なるステップは、
- プログラムの後半部分を理解して、「文章の自動生成」を実感すること。
- 機械学習の元となる文章を増やしたりして、マルコフ連鎖用の辞書のデータがどのように変化するのか、簡単な実験を実施して理解を深める。実験屋の悪いクセ(?)ですが・・・・・・・・。
を考えていますが、まず、1番目の作業を優先させましょう。
***********************************************************