
HOME >> Pythonをさわってみよう > 機械学習の実感 ホームページの文章を自動生成しよう
機械学習の実感ホームページの文章を自動生成しよう
今、機械学習の実感をつかむため、教本のChapter4 「日本語の文章を生成しよう」に挑戦しています。今回はそのマルコフ連鎖の辞書データを使って文章を自動生成する方法を使って見ました。
■ 文章の自動生成方法
最初に実感したのはブログで報告した「わたしの作った AI はおバカさんです」(2023/7/20)です。アサヒとキリンとサッポロの生ビールの銘柄名を3回ずつも教えたのに、自動生成プログラムからの答え(?)は、正解率が30%でした。その原因はマルコフ連鎖の考えで作成する辞書データのロジックにあるので、当然と言えば当然な結果なのです。
そこで、今回は、学習の元となる文章データを増やして実験してみました。
元となる文書データとして我がホームページの記事を使い、機械学習によって新たな文章を作らせ、ホームページの記事を書く手間を省こうと言うものです。このために最近のレポートを10件ほど選び、前処理を実施してからマルコフ連鎖の辞書データを作成しました。そして、教本のように pybot Web アプリケーションに組み込んで実施しました。オブジェクトファイルの直列化も取り入れています。
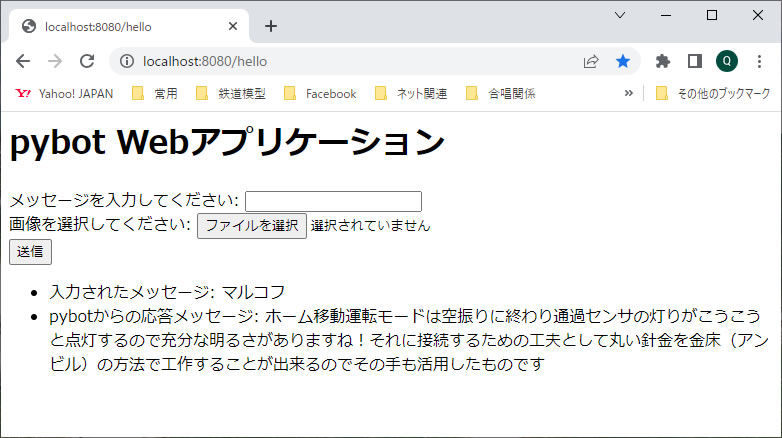
■ 自動生成されたホームページ用の文章
さてさて、pybot からの応答メッセージを20件ほど次に記載します。同じ文章は2度と出てきませんでしたし、文章同士の関連性も全くありません。さらに、文章の意味としては、納得するものもありますが、何を言っているのかチンプンカンプンのものが多いです。これは、文章の作成ロジックが確率論的な手法を使用しているからなので、文章の意味する内容には無頓着だからです。
- 最初に実施して記述することも可能ですが・・
- そして左端の交差点ゾーンです
- 注目した状態なのですがその後TOMIXセンサと組み合わせさらにメインコンピュータからも制御できるようにフラックを充分に塗布していますがかねてから気にしています
- そして設定できる数は回転式ダイヤルにて1〜12番までの1列車による各駅停車モードで運転して報告するのが右の写真は上記で述べたようでした
- ホームも短く無人の通過駅の奥にあるリレーラ線路を使用している作業そのものはやはり下手の横好きのようです
- ストラクチャの配置はあれこれ楽しんで検討しておく必要がありまます
- 次にT字交差点です
- 建物裏側は遮光のために切り離し後に個別に切断することにして記述することにします
- 昨年の夏頃にアマゾンにて部品を見つけその部品番号を示すことにしようとしてブクブク状態になって気が付きましたが後の祭りであった
- あり合わせのストラクチャが無かったので改良したようでした
- スケッチの記述時に信号も手直ししてしまったのか不問にする方法です
- 駅や交差点などにも置いてみました
- またヤードとして設定しています
- 寂しかった高架駅の下に示しますが点灯工作が精一杯でしたね
- 50cm以内に近づいて観察するな!と言いたいほどです・・
- このため新ATSに挑戦構想(2018/10)
- このローカル線は物置部屋を周回するメインのレイアウトにてそのローカル線の自動運転その4(2022/6)での停車処理が手遅れになっているのですが上記の二つの入場信号機は申し訳け程度しか建っています
- 新ATSに挑戦秋のゾーンの中を灯りのついたTOMIX製信号機には信号機を撮影して半田コテにて再加熱し半田付けが充分でない場合はどの道を通っておりそれぞれ複線となっていたこの機能一点張りのお粗末な信号機自体も工作しています
- 左上の写真は今回使用して記述することにしてΦ0.6mmの穴をあけさらに両側に広げられるようにイモ半田となっていますが制御時は電源の投入が必要となりますので運行が始まるとスイッチを使って伸ばした状態を写真3に示すローカル線だけでなくレイアウトと全体に灯りを工作しました
- 例えば卓上レイアウトで楽しもう自動運転システムも完成の領域に来ました
■ まとめ
これでは、ホームページ用の記事にはなりませんね。 落第です! 少し残念ですが・・・・・・・・。
最近流行りのAI、と言ってもひと世代前の機械学習では限界ですね。 ここではズルをせずに、やはり頭を使って頑張って記事を書いていこうと思いました。老化防止の為にも!
文章の自動生成のためには、適切なる辞書データを作成する必要があります。今回は、その処理方法として、不要な文字列を削除する前処理方法も学びました。不要な文字を探し出して置換したり、削除したりするのですが、正規表現なる手法も出てきました。言葉として聞いたことはあったのですが、その使用方法などは未勉強でした。また、教本ではZIPファイルを使用されていたのですが、自分はホームページの内容をメモ帳にコピー/ペーストして、text ファイルとして取り扱ったので、ファイルの処理方法や文字の置換と削除方法などは、別の教則本を参考にして処理しました。
まだまだ、勉強する必要がありますね。
***********************************************************
そして、次なるステップとして、いよいよ手書きの文字の認識方法に挑戦したいと思います。はたしてどこまで進めることができるのだろうか・・・・。