
HOME >> Pythonをさわってみよう > 手書き数字の自動認識 画像処理
手書き数字の自動認識 画像処理
機械学習の実感をつかむため、教本のChapter5 「手書きの文字を認識しよう」に挑戦しています。今回は手書き数字の自動認識に取り組んでいますが、まず、前処理としての画像処理について、まとめておきます。
■ 手書き数字の自動認識の概要
今回も、自分なりに理解した処理の概要についてイラストにまとめてみました。開いている教本は、以前に紹介した
- 書名: いちばんやさしいPython機械学習の教本第2版
- 出版社: 株式会社 インプレス
- 著者: 鈴木たかのり氏、降籏洋行氏、平井孝幸氏、株式会社ビープラウド
です。
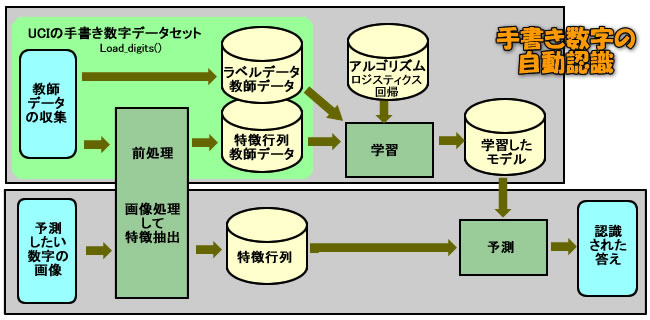
紹介されている方法は、教師あり学習によって作成された学習モデルを使って予測する方法です。その学習データは、カリフォルニア大学アーバイン校 ( UCI )で作成され配布された手書きの数字データセットを使用しています。このデータセットは、約1,800件の手書き画像から画像処理した特徴行列データとその正解データをセットにしたものです。そして、このデータを使って機械学習したモデルによて、予測したい数字画像より文字(数字)認識させようとする仕組みなのです。
教本では、丁寧でわかりよい説明がされていますが、多彩な処理内容と多くのオブジェクトやメソッドが出て来ているので、混乱して整理できない状態となっています。そこで、今回も理解しやすいようにと自分なりにまとめてみました。
まず、全体の流れを教本どおりに実施し、プログラムとして実行できるようにしてから、いつもの様に、いろいろな手書き文字を使って実験をしてみました。その結果としての正解率は、意外にも不合格でした。でもガッカリしていません。このシステムの仕組みを理解できたし、改良すべき点なども分かったのですが。 ・・・・・・・でも、その実力はありません!
*************************************************************
 .
.
■ 前処理の内容
今回は、上記イラストの前処理の部分についてまとめます。ここで実施することは、画像データをコンピュータが処理できるように数字データに持って行くための整形処理を実施しています。そしてその仕上がりの形式は、教師データであるUCIのデータと同じにしておく必要があるのです。
● 手書き数字の写真の用意
右の写真のように、A4のルーズリーフに0〜9までの数字を書いて写真に取り込むことにしました。
写真の処理は、ホームページ用としていつも使用しているMacromedia のFireworks MX2004 を使用しました。そして、これをコピーして各数字毎の写真としましたが、全体の明るさは少し修正したものの、コントラストの調整やシャープ化などの処理は実施していません。
仕上がりのサイズは、約500ピクセル、約350ピクセル、50ピクセル正方形の3種類の画像とし、JPEG形式で保存しました。
● 文字画像を取り込む
文字認識をさせるために文字画像ファイルを取り込みます。
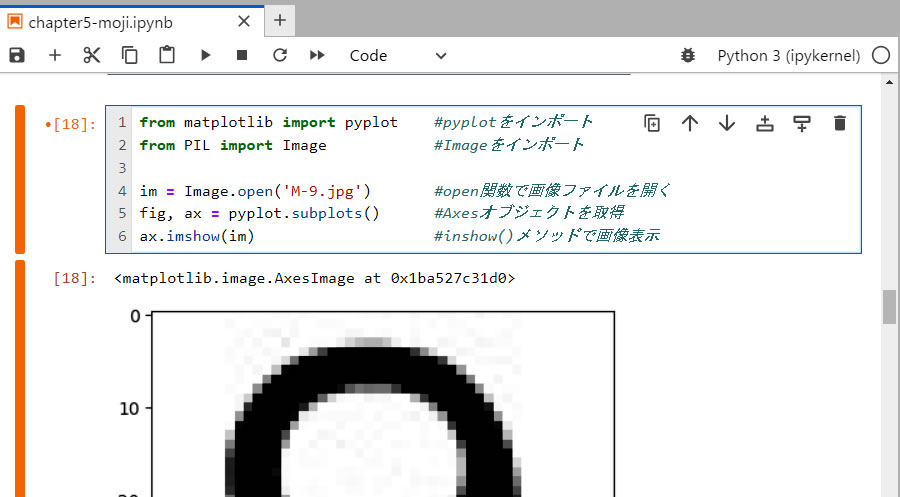
- 1行目: Matplotlib はグラフを書き出すためのライブラリーですが、その pyplot モジュールは JupyterLab に画像を表示させることが出来る。
- 2行目: Pillow (PIL) は、Pythonで画像を加工するためのライブラリーですが、ここでは、その Image モジュールを使用する。
- 4行目: Image モジュールの open() 関数を使用してイメージファイルを開く。そのオブジェクトを im とする。
- 5行目: figure (ひとつの図)の中に、axes (ひとつの座標軸)を同時に描くためのオブジェクトを取得。
- 6行目: その axes (ひとつの座標軸)に、モジュール im を実際に描く。inshow() メソッドでその画像を表示するのだ。 説明によると、matplotlib の Axes オブジェクトの imshow() メソッドを使うと、Pillow の Image オブジェクトを JupyterLab 上に表示できるとのことである。
- なんだかややこしい命令とその関係ですが、さらに勉強する必要がありますね。
 読み込んだ画像データの一部をプログラム画像の下に見えるようにしています。この画像がどのように処理されていくか、見ていきましょう。今回使用している元画像を右に示します。50×50 ピクセルのMSPゴシック書体で、パソコン上で作成した画像です。こんなきれいな文字データを自動認識させると、当然ながら正解率は100%に決まっているじゃん! と思っていましたが、・・・・・・・・・それが答えは「0」でした。 エー?
読み込んだ画像データの一部をプログラム画像の下に見えるようにしています。この画像がどのように処理されていくか、見ていきましょう。今回使用している元画像を右に示します。50×50 ピクセルのMSPゴシック書体で、パソコン上で作成した画像です。こんなきれいな文字データを自動認識させると、当然ながら正解率は100%に決まっているじゃん! と思っていましたが、・・・・・・・・・それが答えは「0」でした。 エー?
● 画像を明瞭にする
次の操作として、画像が明瞭になるように修正します。
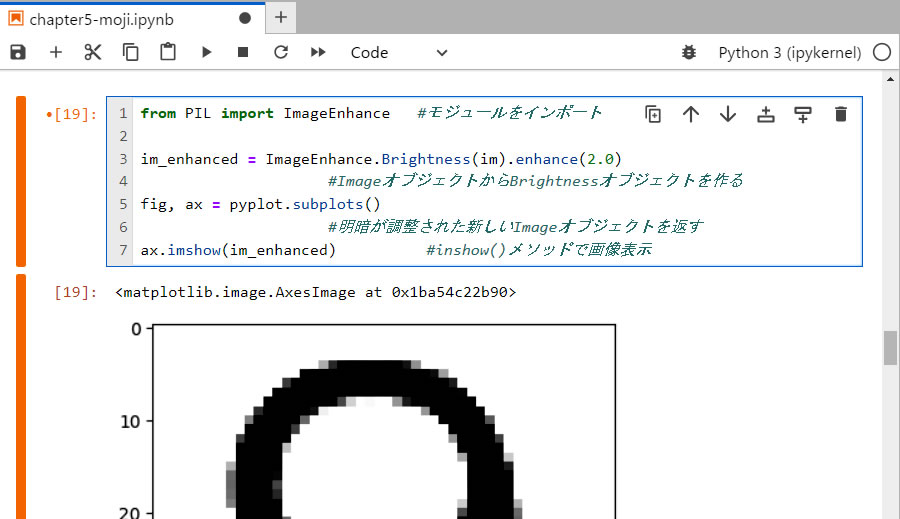
- 1行目: Pillow (PIL) ライブラリーの ImageEnhance モジュールを使用します。
- 3行目: ImageEnhance モジュールの Brightness() オブジェクトを使って画像の明暗を調整する。()内は画像オブジェクトのim を指定する。さらに、enhance() メソッドはその引数が 1.0 より小さいとより暗くなり、 1.0 より大きいとより明るくなります。教本の例では2.0 を指定していますが、この値を目安として調整せよとのこと。
エー? 自動調整ではなくて手動調整なの? これでは自動認識システムではないではないか! - 5行目: 調整された新しい画像に変更する。
- 7行目: 画像を表示する。
- 前の画像にあった背景の薄いポツポツが消し去られ、輪郭も少しはっきりとするようになっています。
● グレースケール化する
手書き文字認識にはカラー情報は不要ですし、邪魔となります。そこで、白黒のグレースケールに変換します。
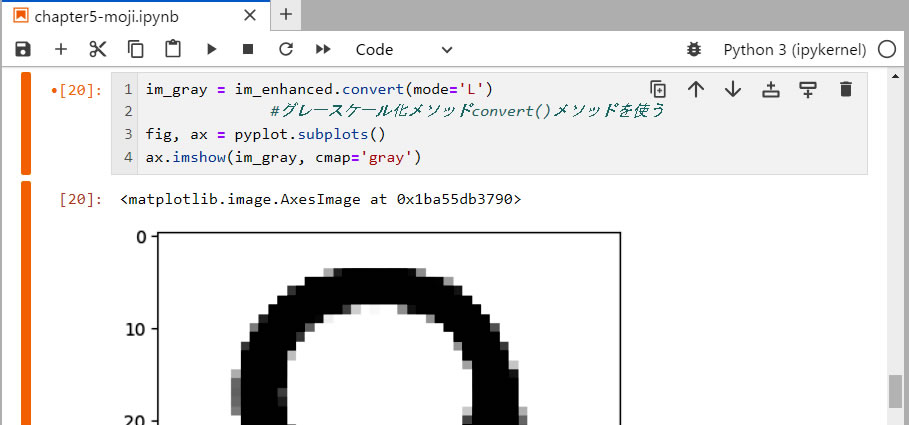
- 1行目: Image オブジェクトのconvert() メソッドを使った、上で処理した im_enhanced 画像をグレースケール化します。 引数 mode の指定は、'L' によって256階調のグレースケールの画像に変換される。 L (8-bit pixels, grayscale)、1 (1-bit pixels, black and white, stored with one pixel per byte)、P (8-bit pixels, mapped to any other mode using a color palette)、RGB (3x8-bit pixels, true color) などが指定できる。
- 3行目: 調整された新しい画像に変更する。
- 4行目: グレースケール化した im_gray オブジェクトを表示します。引数 cmap はカラーマップを指定する。 binary と gray は白黒のグレーですが、白と黒の割り当てが反対となります。
- もともと白黒の画像でしたのでこの処理をしても変化はありませんね。
● 画像を縮小する
手書きされた画像を認識させるためには、学習した教師データと同じサイズにしておく必要があります。そのサイズは、8×8 ピクセルの正方形の大きさです。
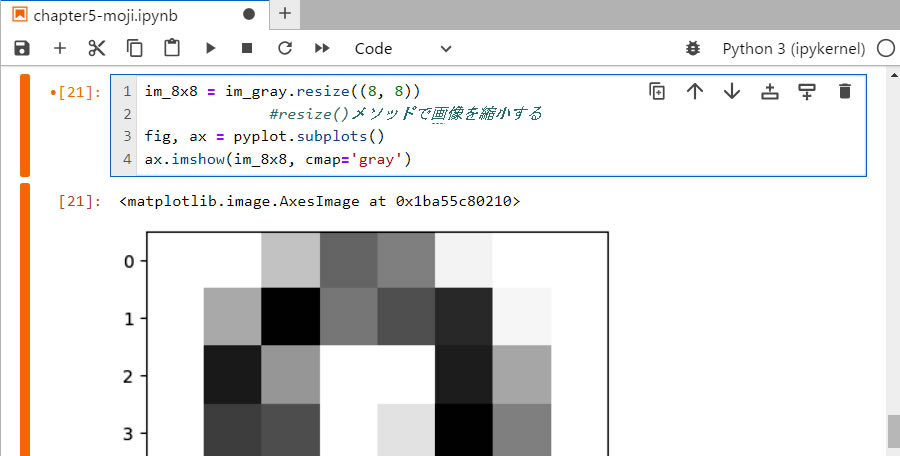
- 1行目: 上で処理した im_gray 画像を resize()メソッドを使って 8×8 ピクセルに縮小します。
- 3、4行目: 処理結果を表示させます。
- さすがに、荒っぽいモザイク画像となってしまいましたな・・・・・・・・・・。
● 画像の明暗を反転させる
最後に教師データと合わせるために、白黒を反転させます。これが最後の画像処理となります。
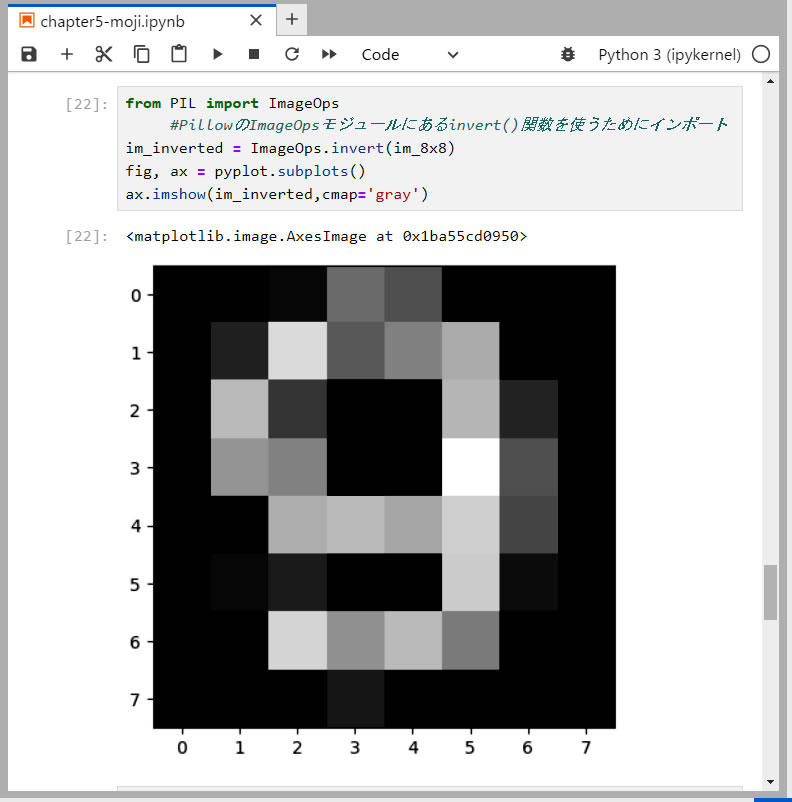
- 1行目: Pillow (PIL) ライブラリーの ImageOps モジュールを使用します。
- 3行目: そして、ImageOps モジュールの inevert() に Imege オブジェクト( im_8x8 )を渡すと明暗が反転されたim_inertedオブジェクトが得られる。
- 4、5行目: 処理結果を表示させます。
- この処理で、前処理としての画像処理は完了です。
■ まとめ
 .
.
画像処理の実質的なコマンドは、上記のステップでは各1行のコマンドで実施されています。従って実際に使用する場合には、このような表示コマンドは省略できます。でも、ステップごとの処理結果をそのたびに表示しておくと、処理の結果が確認できてたので、処理の実際を理解することができました。
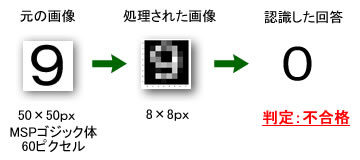
また、この後にも必要な処理を実施して、最終的には文字認識をするわけですが、上記の画像の場合の結果を紹介しておきましょう。
・・・・・・・・・ 自動認識の回答は”0”でした。 ・・・・・・・・
コンピュータが綺麗に描画した文字を、コンピュータは誤認識しているのです! まあ、なんとお馬鹿さんなのでしょうか。
画像認識とはこうも難しい物であることを再認識した次第です。
***********************************************************
さて、次なるステップは、処理された画像データを元に、コンピュータで画像認識が出来るように特殊なデータとして、数値化する方法を見ていくことにします。