
HOME >> Pythonをさわってみよう > 手書き数字の自動認識 学習と予測
手書き数字の自動認識 学習と予測
機械学習の実感をつかむため、教本のChapter5 「手書きの文字を認識しよう」に挑戦し、手書き数字の自動認識に取り組んでいます。先回は、その前処理としての画像処理についてまとめてましたが、今回は学習と予測についてまとめました。
■ 手書き数字の自動認識の概要
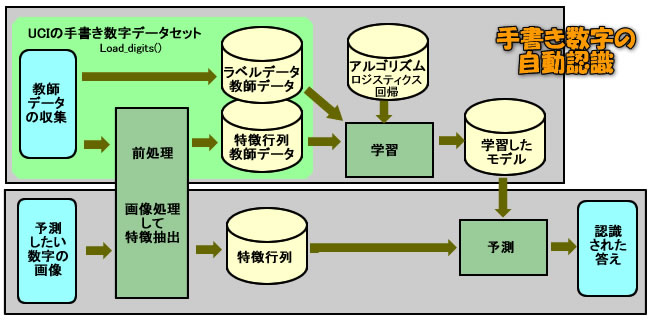
先回の復習として、自分なりに理解した処理の概要についてイラストにまとめてみました。開いている教本は、以前に紹介した
- 書名: いちばんやさしいPython機械学習の教本第2版
- 出版社: 株式会社 インプレス
- 著者: 鈴木たかのり氏、降籏洋行氏、平井孝幸氏、株式会社ビープラウド
です。
紹介されている方法は、教師あり学習によって作成された学習モデルを使っての予測方法です。その学習データは、カリフォルニア大学アーバイン校 ( UCI )で作成され配布された手書きの数字データセットを使用しています。このデータセットは、約1,800件の手書き画像から画像処理した特徴行列データと、その正解データをセットにしたものです。そして、このデータを使って機械学習したモデルによて、予測したい数字画像を文字(数字)認識させようとする仕組みなのです。
.
■ 処理の流れ
処理の流れは、上図のイラストに示すように、
- 多数の手書き数字の画像を画像処理し、特徴行列にした教師データと、その正解をラベルにしたデータセットを用意します。今回はUCIの手書きの数字データセットを使用します。
- 自動認識を実行するための学習したモデルを使用します。このモデルは、データセットを使ってロジスティックス回帰というアルゴリズムを用いて学習させておきます。
- 次に、自動認識させたい画像ファイルを用意し、所定の画像処理した後に、特徴行列を作成します。
- 作成された特徴行列を使用して、学習したモデルによって、予測(判定)を実施します。その回答が自動認識された答えとなります。
今回は、ややこしかった前処理部分以外の部分について見ていくことにします。
■ 学習ずみのモデルの作成
最初に、上記イラストの上半分のフローを見てみましょう。
● UCIの手書きの数字データセットを読み込む
Python の機械学習ライブラリーである scikit-learn には、多くのアルゴリズムやデータセットが用意されているそうです。そこで、手書き数字の自動認識に必要なデータセットだけを取り込みます。
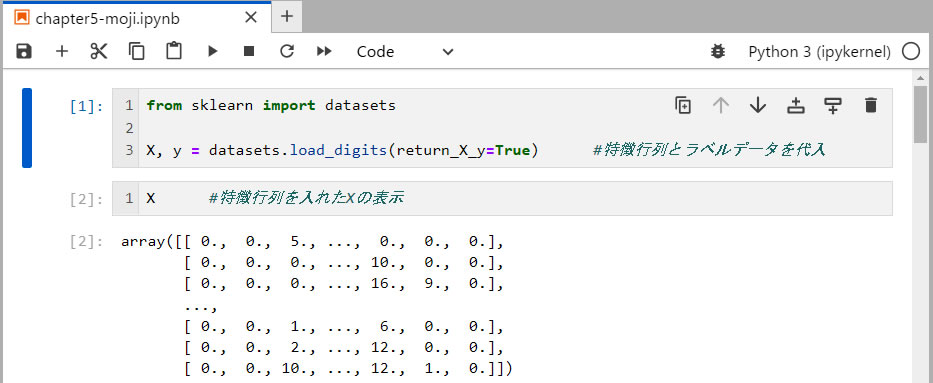

- [1]の1行目: scikit-learn (sklearn) ライブラリーから、データセットをインポートします。
- [1]の3行目: データセットの中のUCIの手書きの数字データセット (load_digits) を読み込みます。このセットの中には説明書なども含まれているため、 return_X_y=True と指定して、特徴行列 X とラベルデータ y のだけを取り出します。そして、特徴行列を X 、ラベルデータを y とします。
- [2]の1行目: ここで、その行列 X の中身を見てみましょう。
この行列は、1,797行の行と、64(8x8) の列から構成され、その数値は、0(白)から16(黒)の数値が割り当てられています。 上記では、始めと終わりの部分を表示し、中間部は大幅に省略されています。 - [4]の1行目: 次にラベルデータの行列 y の中身を見てみましょう。 1行だけのベクトルとなっています。
● 寄り道
ライブラリーである scikit-learn のファイルは、自分のパソコンにどのように納められているのか探してみました。すると、
C:\Users\………\env\Lib\site-packages\sklearn\datasets\data の中に digits.csv.gz (57KB) として収められていました。
意外と小さなファイルでした。そして、この圧縮ファイルを解凍すると、digits.csv (259KB) のCSVファイルとなりました。その中身を下に示します。データセットのまさに数値データの羅列でした。
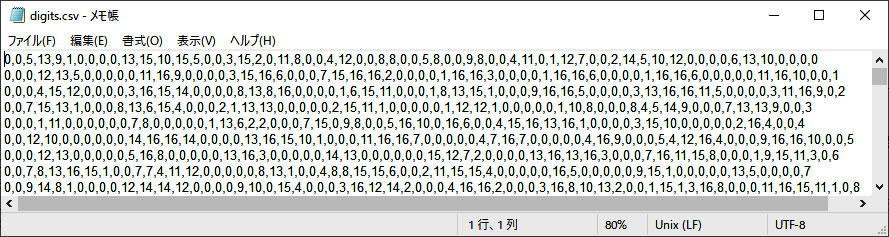
そして、ラベルデータは? と探しましたが見つけられなかったの諦めました。 でも上のデータを見ていると、各行の最後の数字が、行列表示の値と異なっているので、この数字が正解のデータであるラベルデータではないかと推察します。
また、scikit-learn と sklearn の関係がよくわからなかったので、フォルダ scikit_learn-1.3.0.dist-info の中を覗くと、その top_level.txt ファイル内には、ただ一言 sklearn と書いてあるだけでした。なんだかよくわかりませんが、短縮名と言うことで理解しておきましょう。
● モデルに手書きデータを学習させる
scikit-learn に用意されている LogisticRegression と言う名前のロジスティックス回帰アルゴリズムが用意されているので、これを活用します。そして、このアルゴリズムを使って学習ずみモデルを作成します。
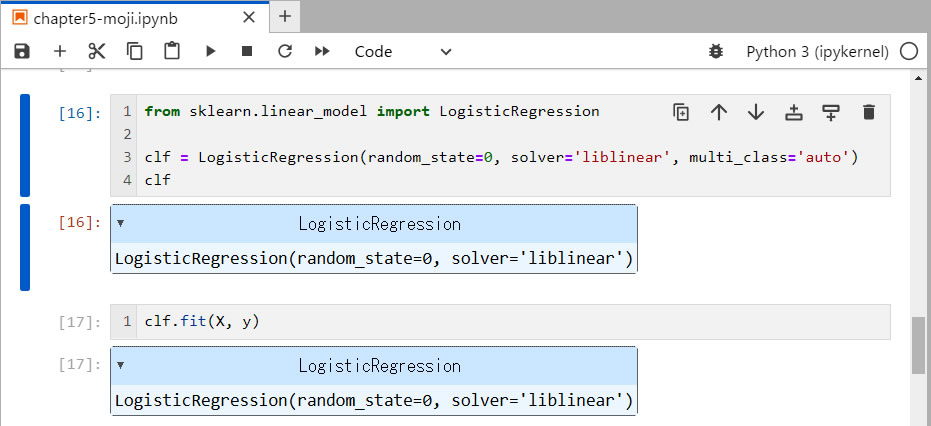
- [16]1行目: scikit-learn の中の sklearn.linear_model から、LogisticRegression クラスをインポートします。
- [16]3行目: LogisticRegression クラスにいろいろな引数を渡して、学習に使用するモデル clf を作成します。引数には、randam_stae 、solver、multi_class などアありますが、他の解説書を見てもよく分かりません。そこで、おまじないとして教本どうりに記述しておきます。
- [16]4行目: 作成されたモデルの内容を表示させているのですが・・・・。指定どうりであることを確認しているのかな。
- [17]1行目: モデル clf の fit() メソッドを呼び出し、第1引数に教師データの特徴行列 X を取り、第2引数に教師データのラベル y を取って実行させると、学習したモデルとなります。 タハーーー! たったこれだけで? 超簡単なコマンドですね!
■ 前処理された画像データを特徴ベクトルに変換
学習したモデルが用意できたので、予測作業の流れを見てみましょう。手書きされた画像を認識させるためには、学習した教師データと同じファーマットにする必要があります。そこで、先回報告したように、画像の前処理を実施します。そして、その画像を機械学習が実行できるように特徴行列に変換します。
● Image オブジェクトから1次元の ndarray に変換する
先回、最終加工した画像の im_inverted を asarray() 関数を使って2次元の ndarry に変換します。これをさらに、1次元の ndarry に変換します。
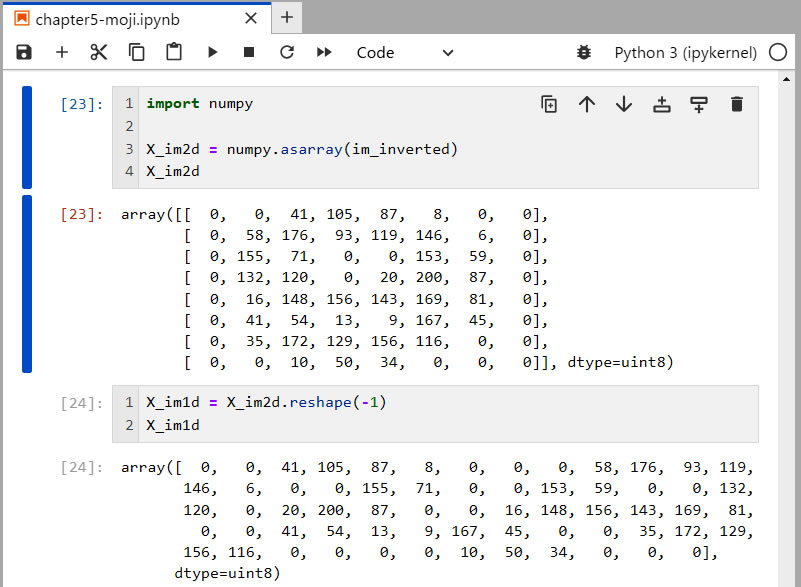
- [23]1行目: 科学計算用のライブラリである numpy をインポートします。
- [23]3行目: numpy の asarray() 関数を使って、画像の im_inverted を2次元の ndarry である X_im2d に変換します。
- [23]4行目: この X_im2d を表示させます。すると、8行8列の行列に変換されているいることが確認できます。そして値は、0〜255の値を取っています。
- [24]1行目: さらに、このオブジェクトを reshape() メソッドに引数を−1にして渡すと、1次元の ndarry である X_im1d に変換します。
- [24]2行目: この X_im1d を表示させます。すると、1行64列の行列に変換されているいることが確認できます。
● 値の数値を0〜16に変換する
最後に教師データと合わせるために、白黒データを0〜16の値に変換します。
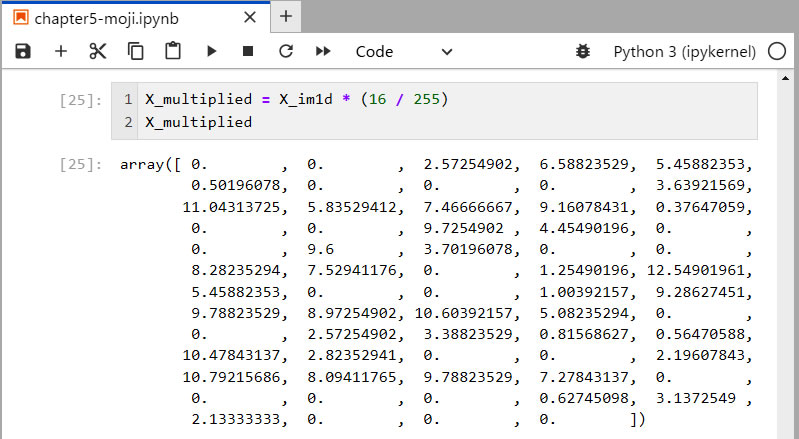
- 1行目: X_im1d の値に16/255を掛けると、各要素に対しても同様な計算を実施し、0〜255の数値が0〜16の数値に変換されます。
- 2行目: その結果のオブジェクト X_multiplied を表示させます。 小数点のある数値ですが、16以下の数値となっています。
- この処理で、テスト対象の手書き数字画像から特徴行列を抽出することが出来ました。
■ 最後のステップ、予測させる
そして、抽出した特徴ベクトル X_multiplied を、手書き文字を学習させたモデル clf にて渡して、手書き文字を予測させます。この時、モデルの predict() メソッドをしようする。
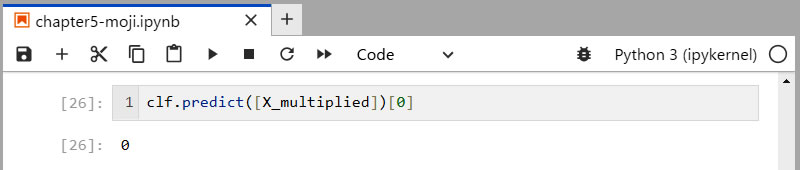
- 1行目: モデルの predict() メソッドに、特徴ベクトル X_multiplied を渡して予測させます。しかし、 predict() メソッドは、ベクトルではなくて、行列を引数にする必要があるので、1件しかないデータなので、[ ] で囲んでリスト化し、その最初の値だけのために[0]を指定するとのことですが、まだ、充分に理解していません。
- たったこの1行で予測を実施しているのです・・・・・・・・・・・・・・・・。
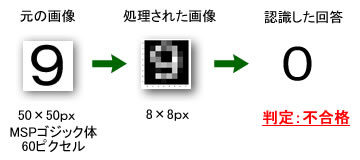
・・・・・・・・・・・ これも驚きですね。 ・・・・・・・・・・ - このコマンドの実行結果が 0 と表示されました。 即ち、手書き画像より予測した数字の答えが、正解の”きゅう”ではなくて”ゼロ”なのです。
■ まとめ
.
実質的に予測を実施したコマンドは、最後の簡単な命令の1行でした。
***********************************************************
自分が一番知りたかった予測・判定のロジックは、完全にブラックボックスとなっていました。でも、そのロジックは公開されているので、調べればよいのですが、小生のレベルでは、その中身を理解することは到底無理であろうと推察します。
でも、先日本屋さんで「Python 3年生 機械学習のしくみ」なる本を目にしたので、思わず買ってしまいました。ロジスティックス回帰について解説されていましたので、こちらも覗いてみることにします。出来たら、その他のアルゴリズムも手を伸ばしてみよう。
***********************************************************
次なるテーマとして、
- 未報告であるいろいろな手書き画像の予測実験の結果報告。
- 教本のLesson46 において、他のモデルとしてランダムフォレストを解説しているので、こちらのモデルを使用した場合の実験もしてみよう。
- そして、上記の新しい教則本の勉強結果も報告出来たらよいのだが。
などを考えています。でも、テーマが「鉄道模型」からどんどん離れていっていますが・・・・・・・・・。