
HOME >> Pythonをさわってみよう > WEBスクレイピングでSLモデルのリストを作ろう
Pythonをさわってみよう WEBスクレイピングでSLモデルのリストを作ろう
苦労して学習したWEBスクレイピング手法の復習として、鉄道模型のリストを作ることにした。自分がコレクションしているNゲージの蒸気機関車は限られているので、市販されている多くのモデルを対象にしてみるのも面白いと考えたからである。
■ 目標の設定
モデルの発売時期は、自分のコレクションを整理している時にどうしても知りたいと感じた項目であった。 そこで、作成するリストには、記載する項目として
モデルの商品名(名称)、その品番、メーカー名、そして発売時期
を記載したNゲージ蒸気機関車のリストとすることにした。
■ 対象とするサイト
メーカーのサイトは、そのメーカーが発売している製品の情報しかないので、販売店サイトを検討した。いつもお世話になっている Joshin、ミッドナイン、ホビーサーチ、ポポンデッタなどのサイトを閲覧して見て、古いデータまで記載されている ホビーサーチさんのサイト にお邪魔することにした。
このサイトは、学習サイトでのアクセス拒否にあった時、初心者の逃げの一手にて一度挑戦したことのあるサイトであるが、もろくも頓挫してしまったサイトなのである。今回はそのリベンジを兼ねて挑戦することにしたのだ。
なお、学習サイトでのアクセス拒否の件は、Python をひとつ前の古いバージヨンにしたり、あるいはrequests のバージヨン指定などで対応できることが分かりました。 内容については、「新しいバージョンでの対応方法」 を参照してください。
このアクセス拒否でうろうろしたおかげで、自分としてはかなり勉強になったと思っています。このため、再挑戦してみることにしたのです。
 .
.
**********************************************************
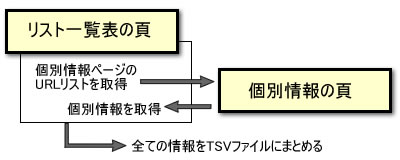
このサイトの構成は、使用したWEBスクレイピング教本のサイトと同じような構成になっています。一覧表の頁には個別情報を記載したページのURLが記載されています。そして、そのリストを取得し、そのURLより個別情報の頁にアクセスして必要な情報をスクレイピングします。
しかし、各ページの記述方法は、自動化されたソフトで生成されているため、複雑な構成になっています。さらに、divタグだけでなく、table タグも多用しています。 このため、教本の方法では目的が達成できず、そのアクセス方法も見いだせずに諦めてしまった次第です。
ホームページに関する豊富な知見と解析ノウハウが必要な事を痛感した次第なのであるが、今回また、あえて挑戦することにしたのだ。ただ、幼稚なPythonのプログラム知識を補うため、「Python ゼロからはじめるプログラミング」を読み直し、文字列の取り扱い方や、タプル、リスト、辞書といった使い方、そしてfor文やif文の文法も再チェックした。使い慣れたArduinoとの違いに戸惑いながら・・・・・・・・・・・。
■ 挑戦その1
まず最初に、上記の方法にて実施することにした。

手順としては、
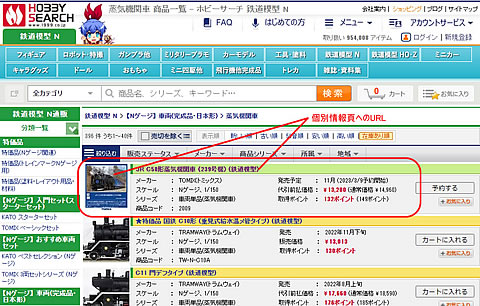
- トップページに於いて、Nゲージの蒸気機関車を選択して上右のように一覧表を表示する。このページに表示されているモデルリストの詳細ページのURLをWEBスクレイピングを使って取得する。<a>タグのURL情報をリストにしていくのだ。
- ただし、URLの記述は相対アドレスで記述されていたので、絶対アドレスに加工する必要がありそうだ。
- 所得したURLリストに従って、詳細ページをスクレイピングするのだが・・・・・・・・・・。右上の図。ここでは、教本で使用していた定義形リストではなくて、テーブル形式で記述されているので、簡単には行かないのだ。
- 求める情報をゲットするためのロジックを検討するのだが、なかなか特定できないのである。テーブル形式で記述されている情報を全部取り出したとしても、そのあとから必要な要素だけを選別するのが、これまた大変な手作業(?)となりそうである。
意気込んで挑戦したものの、やはり諦めることにした。・・・・・・・・・・・・・・・・・・。
■ 挑戦その2
性懲りもなく、またまた挑戦である。 もっと簡単なロジックで必要情報を取り合出せないかと一覧表のページを眺めていた。 眺めていたと言っても、Chromeの”検証”を使ってHTML記述の中身を探っていたのである。そして、下の図に示す部分に注目した。
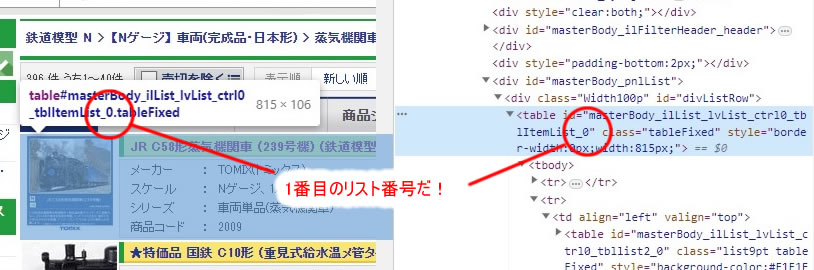
そこで、<table>タグの長たらしい id 番号に注目し、このテーブル内の記述内容を解析した。
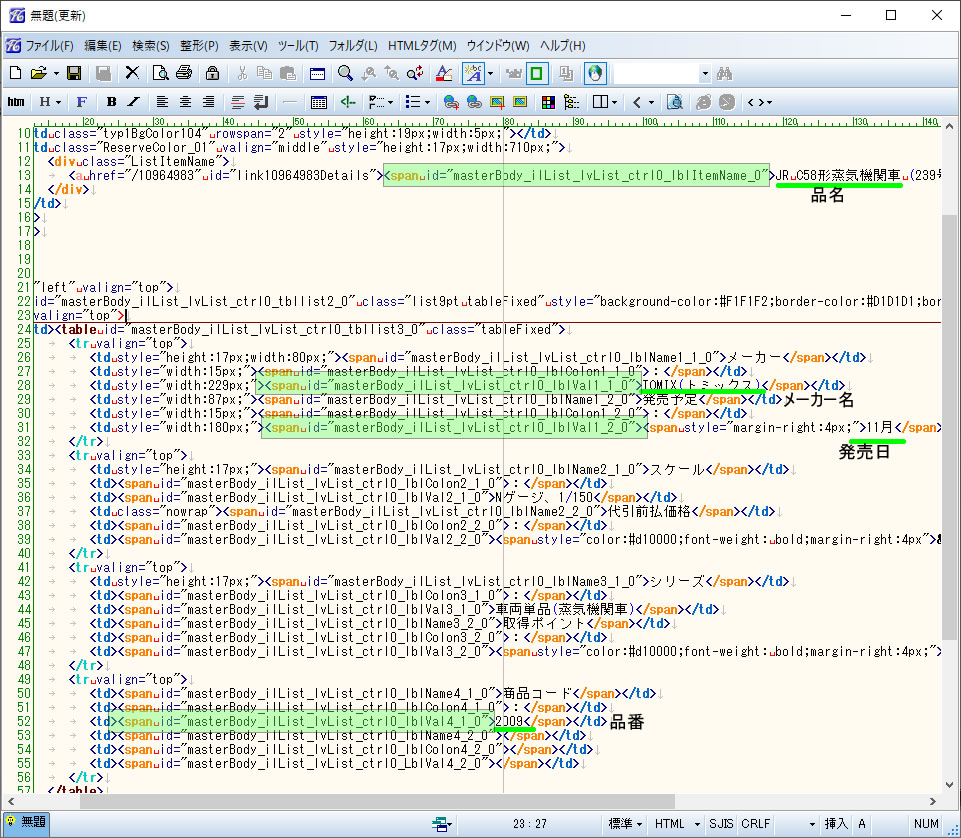
すると、多数の<td>タグの中に、<span>タグが記述されており、その id 番号には個別の識別記号が付与されていることに気が付いた。いろいろ探ってみるとその識別記号は下記のような構成になっていることが分かった。

基本は、「項目指定」部分と「リスト番号」部分である。項目指定は、
- 品名を示す部分は、lbliItemName
- メーカー名を示す部分は、lblVal1_1
- 発売日を示す部分は、lblVal1_2
- 品番を示す部分は、lblVa41_1
であることが分かった。これらは各リストでもおなじであったので、シメシメである・・・・・・・!
また、リスト番号は、一覧表に示された40件のリストに対して、0〜39までの通し番号が付与されていた。ただし、最終頁のリストは途中でストップしていたのは当然であろう。でも、項目指定の前に指定している ctrl0 の項目は何であろうか? 観察して見ると、
- リスト番号が0〜9までは、ctrl0
- リスト番号が10〜19までは、ctrl1
- リスト番号が20〜29までは、ctrl2
- リスト番号が30〜39までは、ctrl3
が付与されていた。10件毎に何か操作しているのだろうか?
とにかく理由は分らないが、この識別記号を利用すると、一覧表のページから必要な情報をピンポイントで、ピタリと取出し可能であることが分かった。
● 検索プログラムの検討
スクレイピングのロジックが分かったので、プログラムを記述することにした。まず最初に識別記号の生成部分から検討しました。製品名を指定するタグのIDが生成できるかプログラムを組んでみたのが下のプログラムです。
for j in range(3):
for i in range(10):
i = j*10 + i
name_id = 'masterBody_ilList_lvList_ctrl' + str(j) + '_lblItemName_' + str(i)
print(name_id)
走らせた結果を下に示す。
masterBody_ilList_lvList_ctrl0_lblItemName_0
masterBody_ilList_lvList_ctrl0_lblItemName_1
********* 省略 ***********
masterBody_ilList_lvList_ctrl0_lblItemName_9
masterBody_ilList_lvList_ctrl1_lblItemName_10
masterBody_ilList_lvList_ctrl1_lblItemName_11
masterBody_ilList_lvList_ctrl1_lblItemName_12
********* 省略 ***********
masterBody_ilList_lvList_ctrl1_lblItemName_18
masterBody_ilList_lvList_ctrl1_lblItemName_19
masterBody_ilList_lvList_ctrl2_lblItemName_20
masterBody_ilList_lvList_ctrl2_lblItemName_21
********* 省略 ***********
masterBody_ilList_lvList_ctrl2_lblItemName_28
masterBody_ilList_lvList_ctrl2_lblItemName_29
見事に、30個の識別記号を生成することが出来ました。そこで、実際のホビーサーチさんのサイトにアクセスし、情報をスクレイプしてみることにしました。Nゲージ蒸気機関車リストの1頁目です。プログラム内容を下に示します。
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.1999.co.jp/list/1703/6/1')
html_doc = res.text
soup = BeautifulSoup(html_doc, 'html.parser')
#div_model_detail = soup.find('div', id='masterBody_pnlList')
for j in range(4):
for i in range(10):
i = j*10 + i
name_id = 'masterBody_ilList_lvList_ctrl' + str(j) + '_lblItemName_' + str(i)
maker_id = 'masterBody_ilList_lvList_ctrl' + str(j) + '_lblVal1_1_' + str(i)
sale_id = 'masterBody_ilList_lvList_ctrl' + str(j) + '_lblVal1_2_' + str(i)
number_id = 'masterBody_ilList_lvList_ctrl' + str(j) + '_lblVal4_1_' + str(i)
model_name = soup.find('span', id = name_id)
model_maker = soup.find('span', id = maker_id)
model_sale = soup.find('span', id = sale_id)
model_number = soup.find('span', id = number_id)
name = model_name.get_text()
maker = model_maker.get_text()
sale = model_sale.get_text()
number = model_number.get_text()
print(name,maker,sale,number)
プログラムを実行した結果は、最初の2件はスクレイピングできたものの、それ以降はスクレイピング出来ずに終了してしまいます。なんで? とばかりにいろいろトライしてみましたが原因が分かりませんでした。
*********************************************
そこで、上記プログラムの8行目の部分をコメント欄として走らせました。この8行目は必要とする情報ブロックを指定したいたのですが、この制約をなくして、ページ全体を検索するようにしたのです。今回のサーチは、ピンポイントで情報を取りに行くので、制限する必要がないと判断したのです。
理由はよく分かりませんが、これは正解でしたね!
実行した結果を下に示します。必要な情報をバッチリと取り出していました。
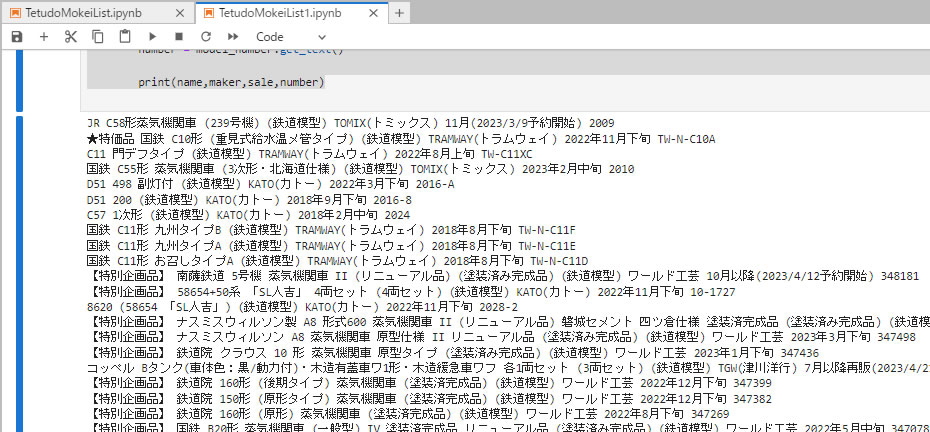
思わず、
キャホー! ヤッタゼベイビー! と思わず叫んでしまいました。
ここまで来れば後は簡単です。教本にならってTSVファイルに出力するようにしました。
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.1999.co.jp/list/1703/6/1')
html_doc = res.text
soup = BeautifulSoup(html_doc, 'html.parser')
model_info_list = []
for j in range(4):
for i in range(10):
# j = 3
i = j*10 + i
name_id = 'masterBody_ilList_lvList_ctrl' + str(j) + '_lblItemName_' + str(i)
maker_id = 'masterBody_ilList_lvList_ctrl' + str(j) + '_lblVal1_1_' + str(i)
sale_id = 'masterBody_ilList_lvList_ctrl' + str(j) + '_lblVal1_2_' + str(i)
number_id = 'masterBody_ilList_lvList_ctrl' + str(j) + '_lblVal4_1_' + str(i)
model_name = soup.find('span', id = name_id)
model_maker = soup.find('span', id = maker_id)
model_sale = soup.find('span', id = sale_id)
model_number = soup.find('span', id = number_id)
model_defin = [model_name.get_text(),model_maker.get_text(),model_sale.get_text(),model_number.get_text(),]
model_info_list.append(model_defin)
with open('model_data-1.tsv', 'w', encoding='utf-8') as f:
for model_info in model_info_list:
f.write('\t'.join(model_info) + '\n')
このプルグラムの使い方は、少し手間が掛かりますが、自分としては充分と考えています。
- 4行目の指定ページのアドレスはページ毎に手で入力し、
- リスト数が40であることを確認し、
- 出力ファイルのファイル名を修正確認し、(上書きされないようにページ毎に新しく作る必要があります)
- プログラム実行します。
- 最終頁は、リスト数を確認し、最後の10個未満のリストについては、上記の11行目を有効にして、j と i の値を指定します。
- 出来上がったページ毎のTSVファイルをもとに、Excel を使って一つにまとめ、形態を整えてリストとして完成させます。
上記5番の項目は、最終頁リストが切れた場合にはループを途中で抜けるコマンドを挿入したのですが、上手く行かなかったのです。あれこれ試したものの、これも逃げの一手で、手動操作を実施するようにしました。
■ 完成したリストの例
Excel ファイルに整理した状態を下に示します。
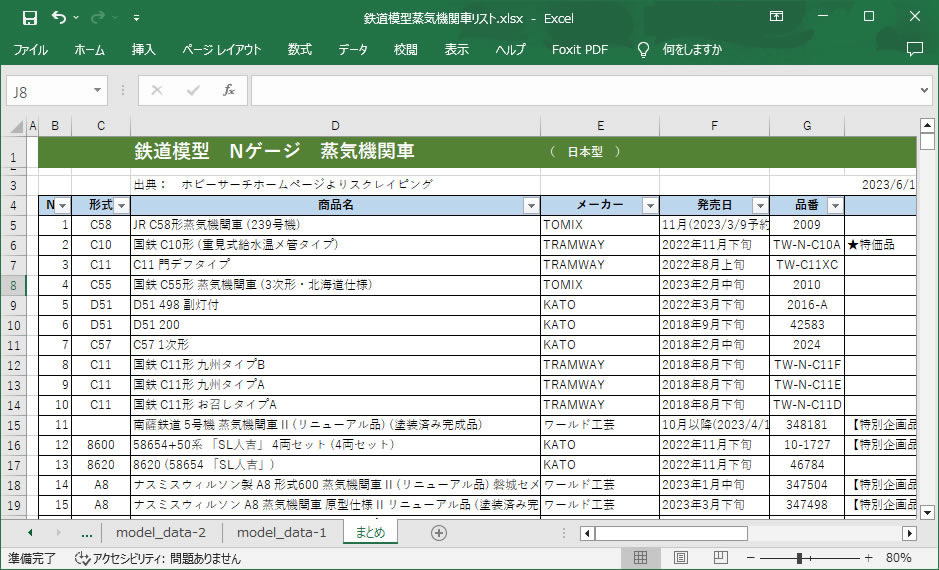
Excel操作も自動化すればよいのですが、WEBスクレイピング出来たことで満足し、後処理は手動で整理しました。なお、KATOの品番について、へんてこなデータとなっていることに後から気が付きました。原因はTSVファイルからExcel にて整理する時に、ハイフォン付きデータを日付けデータとExcel が勝手に解釈して文字化けしたものでした。
また、今回のスクレイピングは、最初に一覧表のページにアクセスしてページデータを取得後は、自分のパソコン内でゴチャゴチャ処理を実行しているため、ホビーサーチさんのサイトには、ご迷惑かけていないと解釈しています。
*****************************************************
WEBスクレイピングの面白さを実感できたことに大満足でした。そこで、次の獲物を狙いたくなりますね!