
HOME >> Pythonをさわってみよう > 近隣の街のコロナ患者発生状況の解析
Pythonをさわってみよう 近隣の街のコロナ患者発生状況の解析
Python と言うプログラム言語をさわっていますが、身近なテーマを使ってその使い方を実感することにしました。 今回は、近隣の街のコロナ患者発生状況の解析を実施したので、まとめてみました。
.
■ 学習のねらい
Python の学習として、実際のデータと自分の頭を使った学習が有用ですよね。 そこで、その簡単なテーマを見つけました。 それが近隣の街のコロナ患者発生状況の解析です。
このデータは、各都市のホームページに公開されていますので、Webスクレイピングの学習となりますし、発生者リストは一件ずつのデータが記載されており、公表日とその人の年代(10歳区切り)も記されています。 そして、このデータを、いま学習している Python 使って解析しようとするものです。
解析の内容は、コロナ患者発生状況の中で気になっていた内容をデータで示せないかと言うものです。 ” 第7の初期は、幼稚園児童から広がっている ” という指摘が本当かどうかを検証してみたいと思ったからです。 このためには、年代別の発生者件数を日毎に示す推移グラフで表示させ、そのパターを観察すれば判断できると考えました。
********* なかなか面白そうなテーマでしょう! *******************
■ 近隣の街のコロナ患者発生状況の情報データ
私の街を含めて、近隣の街のコロナ患者発生状況の情報データをホームぺージから探ってみました。
| 街の名称 | データ提供形態 | 備考 | 結果 | ||
|---|---|---|---|---|---|
| 内容 | ファイル形式 | 発行単位 | |||
| K市 | 発生者のリスト | Excelファイル | 第7波としてまとめたExcelシート | ー | |
| 日毎・年代別件数 | 集計済みのExcelシート | すでに日毎・年代別に集計されており、解析不要でグラフ化が出来た | 〇 | ||
| A市 | 発生者のリスト | 表形態のPDFファイル | 週間・月間データのファイル | 最初に学習した。 | ◎ |
| O市 | 発生者のリスト | 表形態のPDFファイル | 日毎の別ファイル | かなり苦労したが出来た。 | ◎ |
| 全発生者のリス | 表形態のPDFファイル | 過去のデータを含めたひとつのファイル | PDF形式 45MB | ー | |
| T市 | 発生者のリスト | HTMLテーブル表示 |
日毎に別ページ | 途中で中止する。 | 中止 |
| 全発生者のリス | 表形態のPDFファイル | 過去のデータを含めたひとつのファイル | PDF形式 14.7MB | 中止 | |
| C市、N市 | 発生者のリストは未公開 | ー | |||
Python の学習教材としては、Excelファイル、表形態のPDFファイル、HTMLテーブル表示とバラエティに富んだテーマです。 県が集計しているデータを活用している様子ですが、各街によって公開している形態はさまざまです。 でも、解析作業は意外と難しくて勉強になりました。
■ K市の解析結果
K市の場合は、すでに目的とする解析結果が提供されているので、グラフ化処理だけを実施しました。
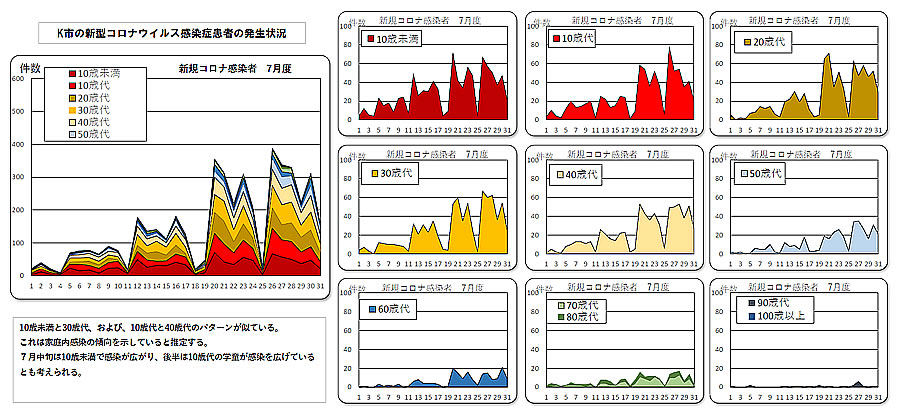
発生者リストもExcelファイルとして提供されているので、自分で解析して結果を比較することも出来ますが、面白くないので実施していません。
■ A市の解析結果
最初に始めたのがA市のデータですが、幸いにも一番取り組み易い例でした。 その内容は「Pythonをさわってみよう 目次」に示す、2022/7/29〜2022/8/7の5件のレポートを参照ください。
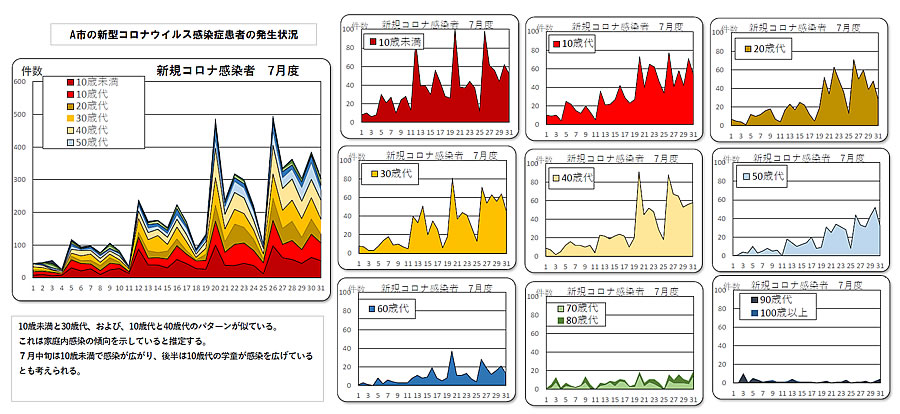
ここで、データの取り扱い方や解析方法の基本を学びました。 最初は、PDFファイルからデータコピペして日別のテキストファイルとし、Pythonで集計していくという全くの初歩的手法から始めました。 そして、Jupyter Lab の環境を整え、PyMuPDF ライブラリーをテストしたり、Tabula-py ライブラリーを使ってみました。 こうして何とかグラフすることができました。
しかし、その後、tabula を使ってPDFの表から日毎のデータをデータフレームとしてまとめ、その結果をcsvファイルとして書出すようにしました。 そして、このデータを年代ごとの集計作業に使いました。 このcsvファイルは処理の中間結果のチェックにもなりました。
さらに、pandas のピポットテーブルの手法を使うと、簡単なコマンドで簡単に集計出来ることも学びました。 楽しくなってきましたね。
■ O市の解析結果
O市のデータに取り組んだのですが、かなり四苦八苦しています。 その様子は「O市のコロナ患者発生状況の解析」(2022/8/26)にて報告しています。
原因は、PDFファイルの内部構成の違いではないかと推定していますが、よくわかりません。 A市と同じ様なPDFなのですが何か違いがあるようです。 ただ、件数が多いためか、日毎のデータとして別ファイルで公開されていいますので、ダウンロードするにも少し手間がかかりました。 ダウンロードの手間は仕方がないとしても、その後の集計作業が少し面倒でした。
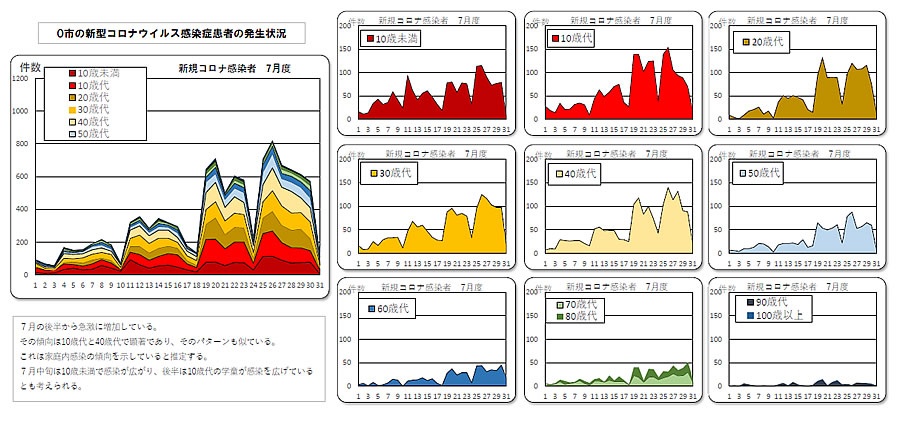
原因は、多数のデータのために、多数のシートが作成されているとみなし、工夫してみることにしました。 その方法として、PDFファイルをExcelファイルに変換し、pandas の手法でシート毎のデータを連結する手を考えました。 このためにPDFファイルをExcelファイルに変換する「いきなりPDF]というソフトをインストールしました。
でも、camelot というライブラリーがあることを知って、問題のPDFファイルがすんなりとcsvファイルに変換できたのです。 さらに、集計の手間を省くため、日毎の別ファイルであるPDFファイルを、いきなりPDFを使って一ヶ月分の一つのファイルに結合し、解析に掛けました。 これは大成功でしたね!
 .
.
■ T市の解析
T市の場合、日毎のデータがHTMLテーブル形式で公開されていました。 右にその画面の一部を示します。 これでやっと Web スクレいピンの学習が出来ると期待して始めました。 上記のO市の解析プログラムを使って、対象ファイルの記述ををPDFファイル名から、ホムページのURLに変更するだけで、容易に対応できました。
しかし、HTMLのテーブル表示で示されたデータは日毎のデータです。 このため、一ヶ月のデータとするためには、同じ作業を31回も実施する必要があるのです。 これを実施する根気がないので解析をあきらめて中止しました。
******* 日別のデータを月別にまとめるにはどうするのか? *********
そこで、過去のデータを含めたひとつのPDFファイルにしてしまえば、O市と同じ方法で処理できると判断して挑戦したのですが、30分経っても終了できませんでした。
その原因はよくわかりませんが、ひとつのファイルであるものの、内容は800ページ以上もある膨大な構成にあるのではないかと推定しています。 この膨大なページをひとつずつ解析するにはたいへんな作業だろうと思われ、時間がかかっているものと思われます。 そこで、必要なページだけを結合してひとつのファイルにし解析すれば時間が節約できると思ったのですが、状態は改善できませんでした。 その他にいろいろな手を考えたのですが、結局学習するには不向きと考えて中止しました。
もし、実施するとなると、最初に日毎のデータを示すHTMLのURLを取得し、そのURLを使って一ヶ月分のデータを取込み、最後にそのデータを集計することになりますが。 そして、この作業を Python を使って実行するプログラムを作成すれば良いのですが・・・・・・・・・・・。 これまたハードルが高くなるので、今回は諦めました。
■ まとめ
Python の学習というよりも、PDFファイルの処理方法に手間取ったような気がします。 また、ネットの情報を取込んでデータ解析を実施するのも容易ではないことも実感しました。 また、Python においては、適切なライブラリーを如何に選択し、それをどうの様に使いこなすかを習得する必要があることも学びました。
- あちこちの説明で Pandas が出てきます。 データ分析で必須と言われるのも納得です。
- PDFファイルを扱うためのライブラリーとして、 PyMuPDF (実行名は fitz )、tabuula-py、camelot を使いましたが、それぞれのライブラリのベースとなっている Java や PostScipt の環境が必要になってきますし、得意とする対象や処理内容も異なっているようです。 どう使い分けるのかは経験が必要なのでしょう。
また、目的の一つであった” 第7の初期は、幼稚園児童から広がっている ” という指摘の検証について、グラフからこの傾向が読み取れることも分かりました。 そしてその傾向は、近隣の街で同じ現象であるものと言うことも言えると思います。