
HOME >> 鉄道模型実験室 > 新しいテープ式室内灯 集電瞬断の解析方法の模索
鉄道模型実験室 No.243 新しいテープ式室内灯 集電瞬断の解析方法の模索
室内灯チラツキの原因である集電回路の遮断状況について、データの収集方法にめどがついた。今回は、そのデータをどのように解析するのか、その方法について四苦八苦したのでその様子を紹介しよう。
.
■ 遮断状況の収集方法
測定装置は、先回の報告「新しいテープ式室内灯 回路瞬断の発生状況 その4」(2024/4/8)と同じである。使用したテープLEDは5ボルト仕様のBTF-LIGHTING 社製 FCOB テープライト 10cm である。電流制限抵抗は、テープLEDの特性に合わせて510Ωを使用し、回路途中に電流の流れを変化させるコンデンサは無しの状態とした。


 .
.
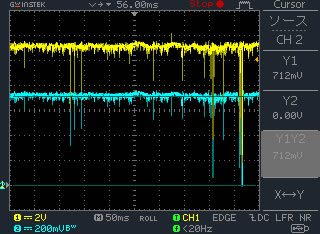
テープLEDはチラツキのある状態でしたので、電流値、即ちシャント抵抗部(R = 51.5Ω)の電圧降下量をCH2で計測した。先回よりも、スイープ速度を早くしたのでチラツキを捉えるタイミングに苦労するが、何度かのトライで観測した。 その手順は、
- オシロのスイープ状態ををオートにして、タイミングを見てストップを掛ける。
- この時のオシロ画面のハードコピーを実施する。右の画面。
- さらに、データ保存のボタンを押して、USBに全てを保存する。すると波形データがCSVデータとして保存される。
こうして保存されたCSVデータを元に解析することにした。
■ 保存されたCSVデータの内容
| Memory Length | 4000 |
| Source | CH2 |
| Probe | 1X |
| Vertical Units | V |
| Vertical Scale | 2.00E-01 |
| Horizontal Units | s |
| Horizontal Scale | 5.00E-02 |
| Sampling Period | 2.00E-04 |
まず、保存されたCSVデータをExcel に取り込み内容を確認する。 ヘッダ部分には設定条件が記されているが、その主要部分を右に示す。
● 縦軸の内容
まず、縦軸の電圧のデータを見てみよう。Vertical Units は V 即ち単位は Volt であることを示し、その Scale は 2.00E-01 である。これは縦軸の目盛りが 200mVであることを示している。 さらに、このオシロでは、ひと目盛り(桝 div )を 25 の point としてデジタル値で保存しているので,
Vertical Scale 200mV/div 、1div = 25 point だから、1 point = 8 mVolt となる。
シャント抵抗値は、R = 51.5Ωなので、1 point = 0.155 mA と換算出来る。 このCSVファイルでは、このデジタル値で保存されているのだ。
● 横軸の内容
横軸は時間軸であるが、Scale は 5.00E-02 である。これは横軸の目盛りが 50msec であることを示している。さらに縦軸と同様にひと目盛り(桝 div )を 25 の point として表示しているので,
Horizontal Scale 50ms/div 、1div = 25 point だから、1 point = 2 msec となるのだが・・・・・・。
しかし、時間軸の場合はデータのサンプリング時間はさらに細かく実施されており、Sampling Period として 2.00E-04 即ち、0.2msec で実行していることが記されている。そしてファイルには、Memory Length は4000 個のデータが保存されているのである。 これは、0.2msec × 4000 = 800msec の間のデータをこのファイルが保存している事を示している。画面表示部分よりも広く保存されているのだ。
● データの内容
次に実際のデータを見てみよう。4,000 個のデータなのでグラフにして示す。左のグラフは全データを表示し、右のグラフは一部のデータを時間軸を拡大して表示している。
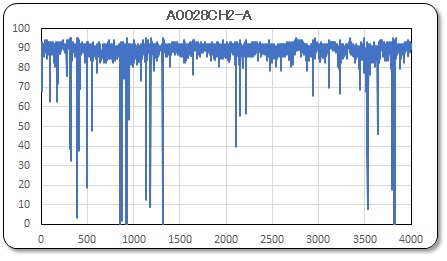
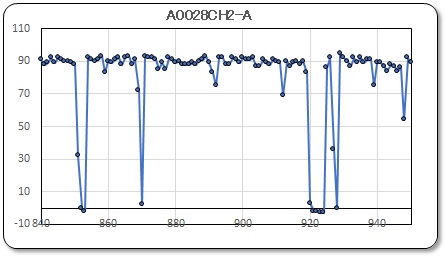
また、グラフの縦軸は、上記に示した point 単位で示し、横軸は period 単位として示している。即ち、1 point = 8 mVolt であり、1 period = 0.2 msec である。縦軸の平均ポイントはおよそ90なので、電流に換算すると 0.155 mA ×90 = 13.95 mA となる。横軸は 0.2msec 間隔でプロットされている。
■ データの解析方法の模索
対象となるデータを収集することが出来たのであるが、さて、これらをどうやって解析して集電回路瞬断の頻度データとするのかが問題なのである。グラフとして示して、「こうでした」と言うだけでは意味が無いのである。「新しいテープ式室内灯 チラツキの限界を探る」(2024/3/24)や「新しいテープ式室内灯 チラツキの限界図」(2024/3/25)の知見とどう結び付けるのかが思案のしどころである。
**************************************
幾つものグラフをしげしげと眺めていて、思いついたことを羅列してみよう。
- 瞬断時のパルスは、意外と短い時間のパルスが多い。まさにノイズの様である。いや、ノイズかもしれないのだ。
- 今まで考えていたチラツキ時間幅の単位は 0.05〜0.1秒の認識でいたが、上記のチラツキの限界実験から感じていたように、一桁短い時間で検討する必要を改めて感じた。
- パルスの形状には、V字谷とU字谷がある。
- U字谷の底はゼロまで落ちている。これは途中の状態が無いONかOFFかの現象ともいえる。
- 中には、V字谷が連続すると、平均して中間的なU字谷と見ることも出来る。
- V字谷形のパルスは、パルス幅が小さいので、人間の眼には感じないようである。
- そこで、パルス幅の大きいU字谷に注目しよう。
という事で、このパターンのデータを切り出して、その頻度を探る事にしよう。これを手作業が実施るのは大変なので、少しかじったPythonを活用することにした。
**********************************************************************
# CSVデータの上部を削除してデータだけにしたExcelファイルを読み込む。 import pandas as pd path = 'C:/Users/Meito/Desktop/michi/chiratuki-kaiseki/ALL0028/A0028CH2-A.xlsx' data = pd.read_excel(path) # データを整形する。前後3個のデータを平均化。 data1 = pd.Series([]) for i in range(3997): a = data.iloc[i,0]+data.iloc[i+1,0]+data.iloc[i+2,0] a = int(a/3) if a > 85 : a = 90 data1[i] = a data1.to_excel('A0028CH2-B.xlsx',sheet_name='output1') # パルス部分を切り出す。 data2 = pd.DataFrame(columns=["Data_No","Memory_No","Priod","dmin"]) data2.set_index("Data_No",inplace=True) tani = 0 dmin = 90 Priod = 0 Data_No = 0 for Memory_No in range(3997): if data1[Memory_No] < 90 and tani == 0: tani = 1 elif data1[Memory_No] < 90 and tani == 1: Priod = Priod + 1 if data1[Memory_No] < dmin : dmin = data1[Memory_No] elif data1[Memory_No] == 90 and tani == 1: data2.loc[Data_No] = [Memory_No,Priod,dmin] Priod = 0 tani = 0 dmin = 90 Data_No = Data_No + 1 data2.to_excel('A0028CH2-C.xlsx',sheet_name='output2')
● パターンの切り出し方法
いろいろな考え方でトライしたが、最終的には次のようなロジックとした。
- CSVファイルから上部の部分を削除してデータ部分のみとしたExcelファイルを取り込む。
- 細かな変動を取り去るために、前後の3個のデータを平均化して新なデータとする。
- 通常状態でのゴチョゴチョした変動を無視するために、ある値以上は、一定値とする。
- その一定値から落込み始めたタイミングを谷の入り口とする。
- 谷も出口は、一定値に戻ったタイミングとする。
- 谷の入り口と出口の幅と、その間の最小値を記録する。
- この値と、出口の位置をデータとして書きとめる。
- この作業をファイルの最後まで実施し、最後に処理データを出力する。
● Python の記述
上記のロジックを Python で右の様に記述した。作業環境は Jupyter Lab を使用し、ライブラリーとして Pandas を使う。
- Excelファイルからデータを読み込み、data とする。
- まず最初にデータの整形を実施する。
- 1列のデータ data1を準備しておく。
- data から1行づつ読み込み、3個のデータの平均をdata1に保存する。
- その値が 85 より大きければ一定値である 90 にする。
- 後からデータの検証が出来るように -B 付けのデータとしてExcel形式で出力する。
- ここから、パルス部分を切り出す作業に入る。
- 列名が Data_No 、Memory_No、Point、dmin の4列のデータフレームを準備する。
- Data_No 列を index 列として指定する。
- 各変数の初期値を設定する。
- data1から順番にデータを読み込んでいく。この時の順番を Memory_No として、元データとの参照付けを行う。
- 読み込んだデータが 90 以下であれば谷の入り口と判断し、谷の中であることを示す変数を tani = 1 とセットする。そうでなければ次のデータを読み込む。
- 90 以下で、かつ、谷の中であれば、時間幅 Priod をひとつ加算し、その値が最低値であるかを判断する。もし最低値でありば更新する。そうでなければ次のデータを読み込む。
- 次のデータが 90 で、かつ、谷の中であれば、谷の出口であると判断して、パルスデータをdata2の行に追加する。そして、関係する変数を初期に戻す。
- data1 のすべての行をチェックしたら、最後にdata2 の内容を -C 付けデータとして Excel 形式で出力する。
Data_No |
Memory_No |
Priod |
dmin |
0 |
11 |
2 |
81 |
1 |
95 |
2 |
82 |
2 |
173 |
2 |
82 |
3 |
182 |
2 |
85 |
4 |
272 |
0 |
90 |
5 |
310 |
2 |
69 |
6 |
319 |
2 |
73 |
7 |
388 |
2 |
62 |
出力された Excel データの一部を右に示す。この出力データをみて、プログラムミスに気がつきましたが、影響ないと判断して修正していません。Priod = 0 の場合があったのですね。1回だけ谷に入ったものの、すぐに出てしまったのでこのカウントが進まなかったのです。
■ 思わぬトラブルに!
今回の検討のなかで、数日もウロウロした事がありました。それは、上記の14番目の処理方法です。
**************************************
新しいデータを Pandas の DataFrame の行に追加する場合、多くのネット情報では、例えば
df1 = df1.append(df2,df3,df4)
と記述すればよいとの事でしたので 、そのように記述したのですが、no attribute のエラーが出てしまい、プログラムが実行できませんでした。
**************************************
他のネット情報も試したのですが、同様でしたので諦めかけましたが、やっと貴重な情報にたどり着く事が出来ました。その内容は、
2023年4月、pandas 2.0がリリースされた。
そして、pandas.DataFrame.append()が削除された。
Pandas 1系では、Dataframeに新たな行を追加する関数としてpandas.DataFrame.append()が用意されていた。
しかし、Pandas2系ではpandas.DataFrame.append()が削除された。1系の時点ですでにDeprecateであったのが、2系で削除された格好だ。
このため、no attribute としてエラーとなってしまう。
即ち、行追加のメソッドである append は、バージョン2以降は使用禁止となってしまっていたのである。 Pandas のバージョンが古いと思って最新版にアップロードしたのであるが、逆だったのである。そして、プログラムの様な記述方法が紹介されていたの早速採用させて戴きました。
data2.loc[Data_No] = [Memory_No, Priod, dmin]
Data_No は上記の9番目の処理によってindex 列として指定されているので、この番号の行の蘭にデータを書き込むのである(と解釈している)。
たったこれだけの事であるが、上手く行かずに何度もあきらめかけたことか! 古くなっってしまった情報のメンテナンスがいかに大切であるかを知らされたが、また、そのメンテナンスは難しいことも承知している。
**************************************
次回は、このプログラムを使って切り出された情報について紹介しよう。
2024/4/9